
[#87] The Agentic Commerce Stack (Part 2): Agents don't need less data. They need a better trust and privacy layer
To enable agentic workflows at scale, redacting data or keeping everything in-house isn't the answer. We need a trust and access layer that's programmable, provable, and portable

In Part 1 of this theme, I mapped out the protocol landscape for agentic payments, which was A2A for discovery, MCP for context, x402 and Stripe for payment execution, and the missing privacy layer that nobody’s built yet. But protocols are abstractions.
To understand where they break, you need to look at what an agentic workflow actually looks like today - step by step, data field by data field. That’s what this piece does. I’m going to walk through a real multi-agent flow (a complaint handler delegating to a refund bot), trace every piece of data that moves, show where sensitive information leaks, and then build up a 5-layer data governance framework that I think is the minimum viable stack for making any of this enterprise-ready.
If you haven’t read my previous piece, here’s the link:
[#86] The Agentic Commerce Stack (Part 1): Works for low-risk flows, not for secure scale (yet)
![[#86] The Agentic Commerce Stack (Part 1): Works for low-risk flows, not for secure scale (yet)](https://substackcdn.com/image/fetch/$s_!PuNR!,w_1300,h_650,c_fill,f_webp,q_auto:good,fl_progressive:steep,g_auto/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F36c6e0ce-69e7-4b65-9e6f-3a196b4ef443_1630x920.png)
The AI industry has spent the last two years building agents that can reason, use tools, and talk to each other. Google’s A2A lets agents communicate. Anthropic’s MCP lets them access tools. Payment protocols are emerging so agents can transact autonomously. But there’s a problem nobody has cleanly solved: when Agent A from Company X collaborates with A…
Let’s jump in.
This is what the agentic workflow looks like today
Assuming everything is set up, agents are created, and a task is defined, this is what an agentic workflow looks like today. Let’s go through an example, and it will illustrate better what the gaps are, in what we’ve been talking about in the first half of this article.
There is a task that triggers an agent, and the example I’ve used below is that of a Complaint Handler for a Payment Aggregator. This is a high level flow just to illustrate how some of these things are working in a multi agent flow today, and helps me illustrate my point better about how privacy & data, and subsequent audit and traceability logs are what we need to actually make this scale. This is the flow today:
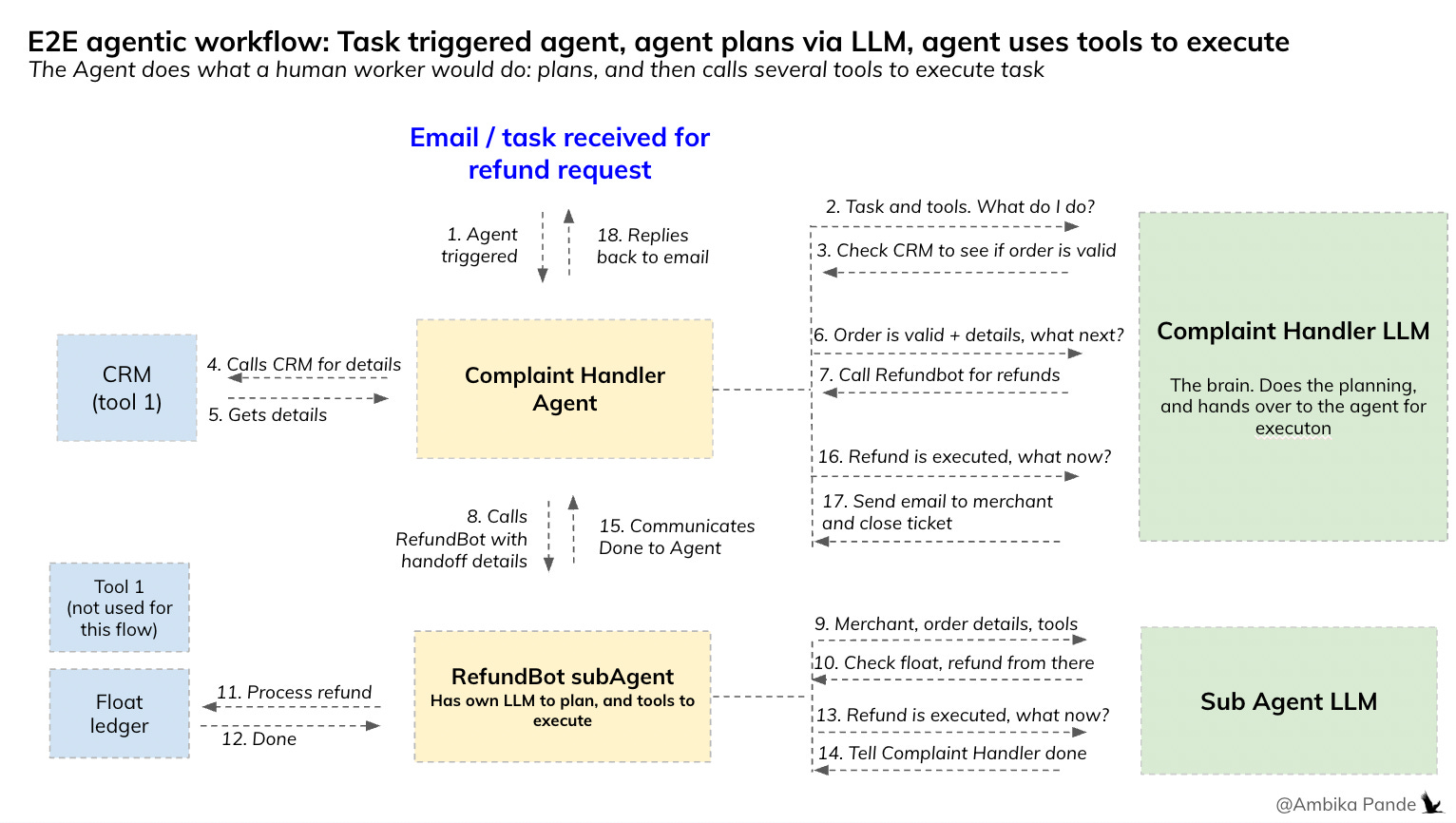
Just summarizing the above diagram. Essentially the flow looks like this
Some task (in the above) it is an email triggers the agent (the Complaint Handler Agent) in this case
The Complaint Handler Agent sends email, and the tools to its ‘brain’ which is the foundation model / LLM, which could be GPT, Anthropic, and asks it what to do
The LLM takes the input and the tools, and translates to actions, which it then feeds back to the Agent, and the Agent executes. In this case, the task is to process a refund, so the Complaint Handler agent sends the details to the LLM, which first tells it to check the CRM (a tool), and then after it confirms that the merchant is valid, delegates to another agent, which I’ve called RefundBot - the refund management agent
For RefundBot to be able to do its job, which is process refunds, the Complaint Handler Agent needs to send it all the context from the conversation, which is merchant details, amount, type, and depending on how systems are structured, to actually enable money transfer, will need data such as account numbers.
RefundBot then takes all that information, and the tools it has at hand (which could be Float Access / Pre-paid wallet for refunds, some sort of merchant detail look up, whatever it is, and sends it its own brain. Since this is a sub agent, it is possible it has its own LLM set up.
The LLM then sends it back the next steps, which could be different depending on what the input is: example - a 3 day old order probably has a different refund process vs a 45 day old order. The RefundBot then calls the tools it has access to to execute, completes the task, and then communicates this back to the Complaint Handler
The Complaint Handler then responds back to the email / task, and closes the ticket.
This is where the point about context and memory becomes important. For Multi Agent workflows to work, you have to be able to share data, context, and store in the agent memory
The problem here is, that you’re sacrificing convenience over privacy. At every step, the Agent is either sending extremely sensitive information to a LLM, which is a third party, or to another Agent (RefundBot in this case). In both cases, at a personal level, users may still be okay to share some of their details to avoid overhead, the logic being, that they would be sharing this in any case At an Enterprise level, this is akin to sharing private, confidential data that you cannot share by law, and data that constitutes a competitive advantage, with absolutely no checks and balances.
To illustrate this better, in the simple above flow, I have mapped out where and what data is actually moving. I’ve tried to rank it basis internal / external sharing (which is also a risk by the way, with sensitive data, there is also a limit with what you can share with internal functions), and how sensitive the information is.
In almost every step, where the Agent needs to send details to the LLM to plan, or the Agent needs to delegate to another agent is where there is breach of data
If I had to break down the flow of data, this is what every task looks like in the above flow. Which is actually quite simple and straightforward if you think about it. Out of the 22 steps, ~50% of them require some sort of information or data to be shared with the LLM, or with the next agent so that they can plan and execute.
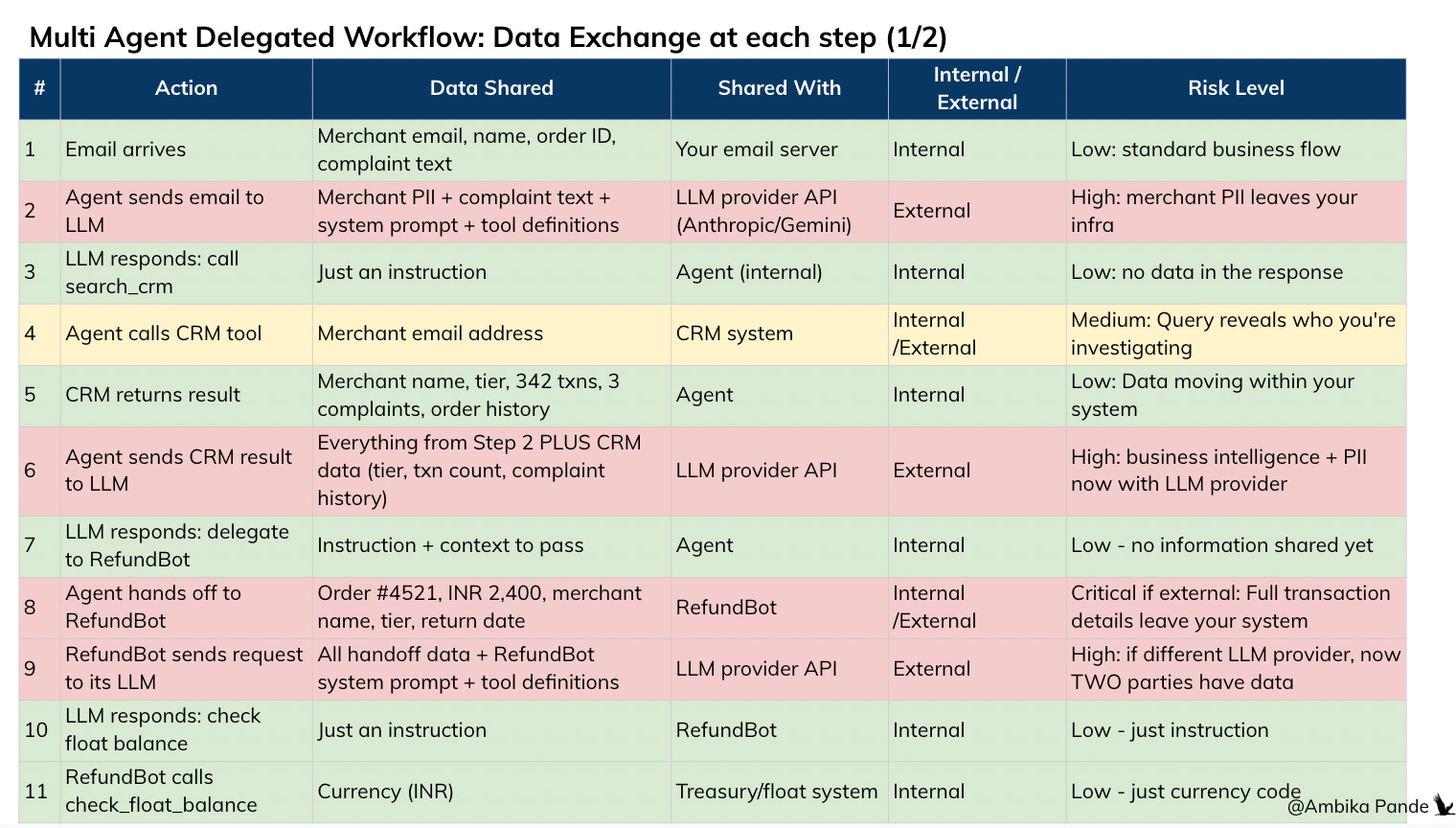
And the thing is, you NEED to share this data and context. The real value of AI, and these agentic workflows is if you can give them AS much context as you can, as much data as you have, and then let them execute. The risks: this is just really personal data you’re trusting a third party with. An individual user may not really be aware about all this. For an Enterprise customer, they are required by law, and by the trust their customers have put on them to ensure that none of their sensitive data is leaked.
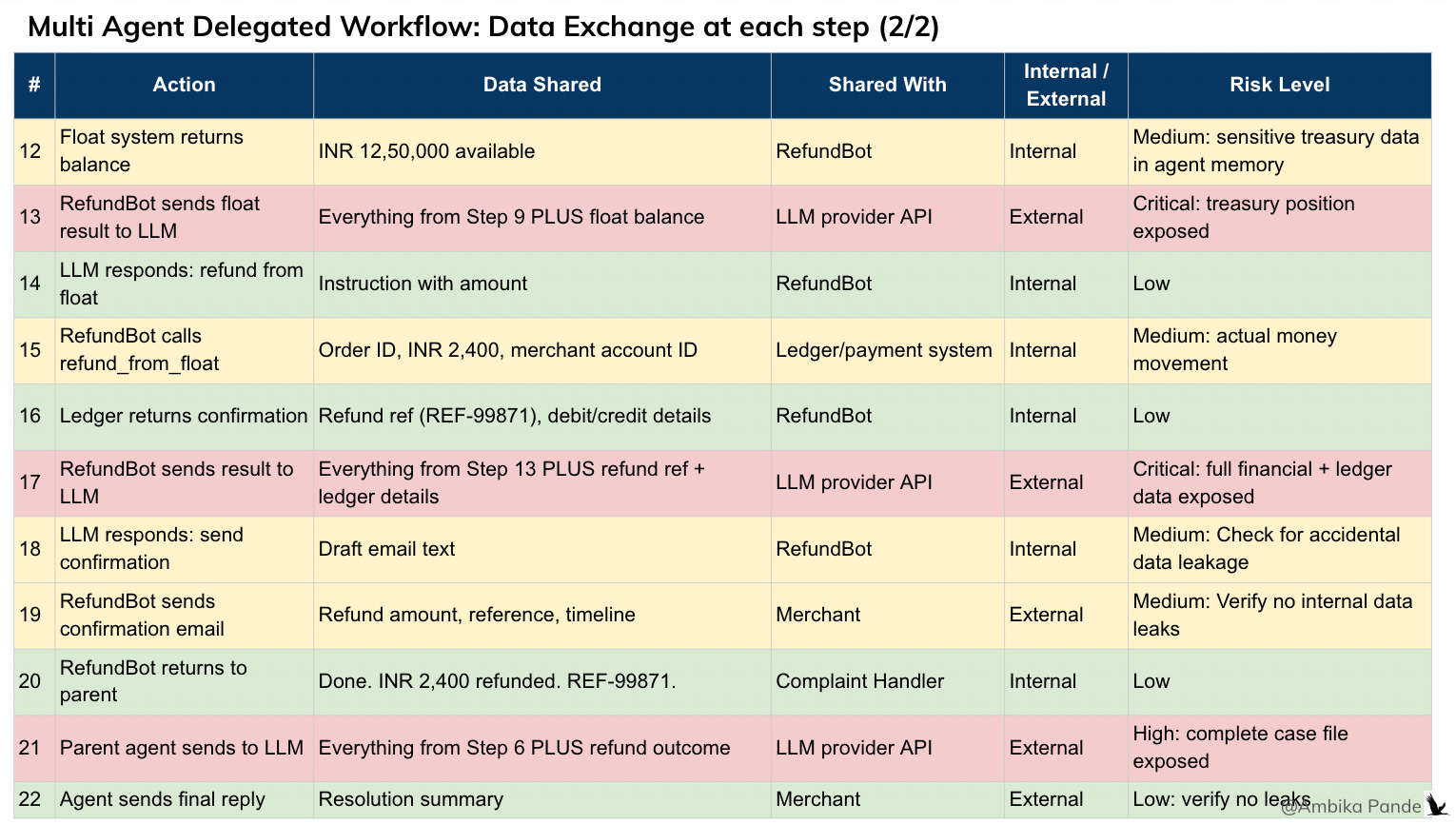
And that is the challenge. No enterprise deployment is going to happen if these gaps are not solved. And this is where we need to draw the distinction: somewhere, the reading the data, and acting on the data needs to be separated. That is what I mean when I say that context and memory are needed, but powered by security and privacy.
But here is what truly makes them enterprise ready - how do you puts checks and balances on this layer?
Again, very first principles thinking. But to be able to put checks and balances, we need to first take a few steps back. Checks and balances on what? This is how I have thought about the data governance stack for Agentic AI
Layer 1: The Context Graph: What data is actually flowing, and what is needed at each step.
If you don’t have data visibility, then you don’t have anything. You can’t build or protect something you don’t know. So Layer 1 would be to map this out per workflow. Example: In this article, I have talked about the Complaint Handler, and the RefundBot, and mapped out what data and tools they are touching, and where is being sent. Ideally, this should be mapped out for every agentic or A2A communication in the enterprise (or personally as well). This is my definition of the context graph. And I am calling it ‘my definition’ because there are a lot of different definitions floating around. Some papers define it as a knowledge layer, while others define it as shared context between agents, and so on.
A context graph is a structured representation of how data flows through a system, capturing for each interaction what data fields are present, their source, which agents access or transform them, and which internal or external parties receive them. It goes beyond tracing flow by encoding the minimum data required for each decision, along with the policies that govern what is allowed, restricted, or prohibited at every step.
Crucially, a context graph is not just a static view of data movement, it is a policy-aware model that evolves over time, linking data, agents, and permissions to ensure that every piece of information is used only in the context it is intended for.
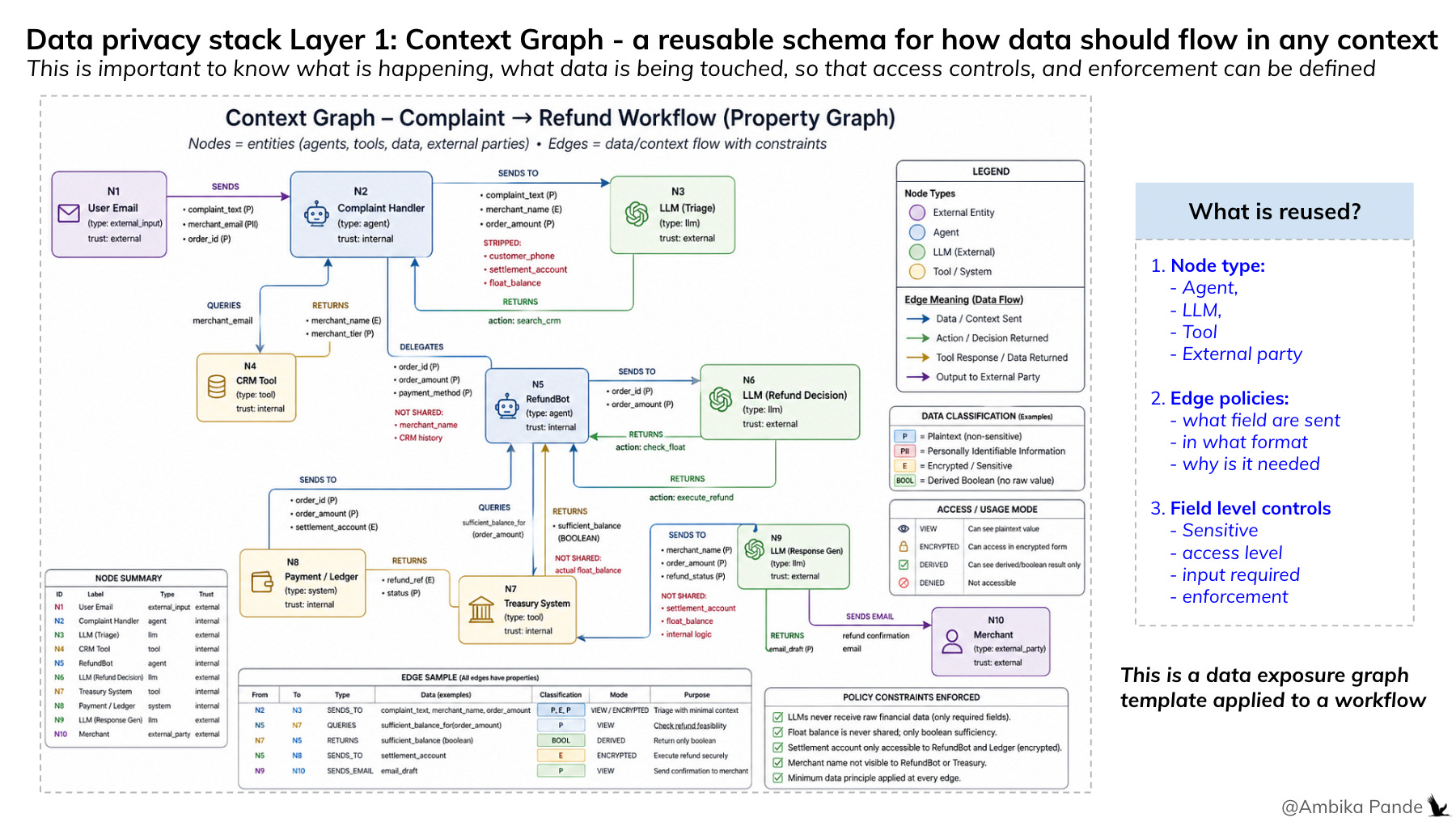
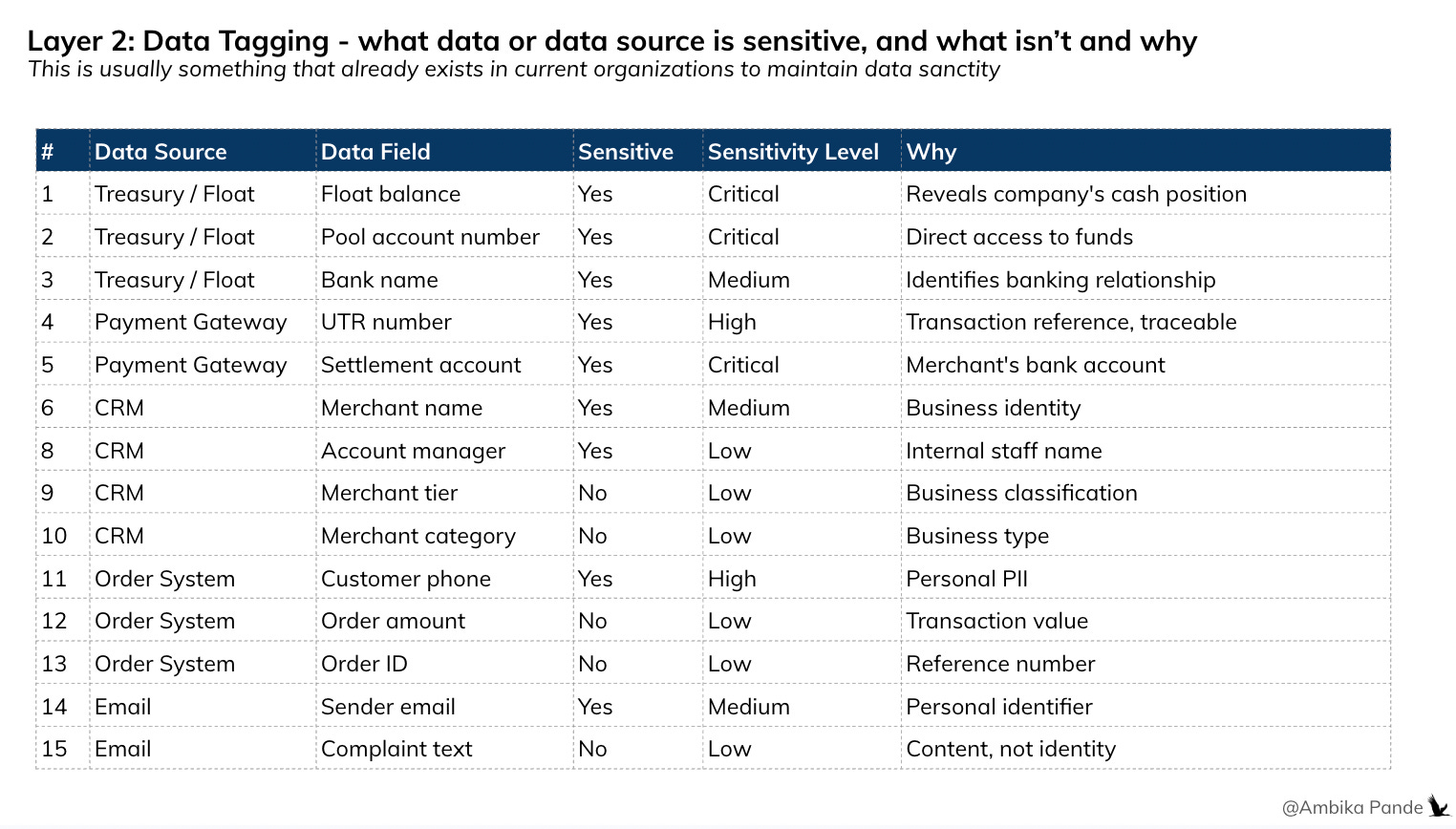
Layer 2: Data tagging. Is the data sensitive?
This layer defines if the data field sensitive or not? That’s it. This is a property of the data itself, defined at the enterprise level, not per workflow. However, this is a big task, so it is probably easier to tackle it per workflow. Example: The Complaint Handler, and the RefundBot would have access to information such as merchant_name, account_details, refund_amount, merchant_category, order_days, and even things such as float_balance, float_account, customer_phone etc. Some ways to tag this:
Float_balance → sensitive.
customer_phone → sensitive.
order_amount → not sensitive.
complaint_text → not sensitive.
This is a master classification that the enterprise maintains once. Similar to how banks already classify data as PII / non-PII / restricted - just applied to agent context fields.
Layer 3: Access control - who should get what data, in what form?
This becomes a per agent, per step: should this agent access this field? If yes, does it need the actual value, or just a verification? This is where the intelligence lives. It could be the same field, different answers per agent, and for different steps.
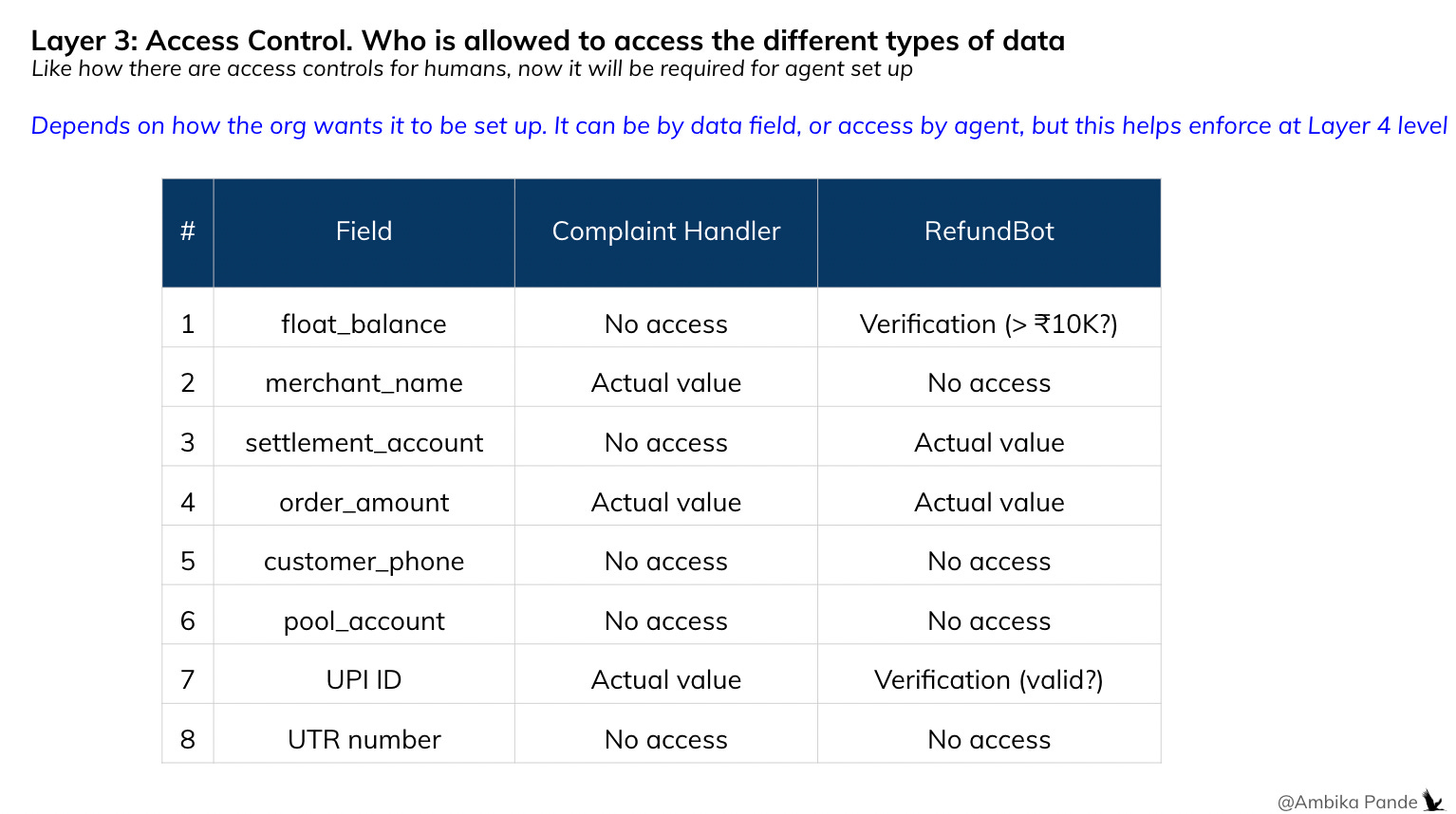
So, after layering the data, or rather, the source of data as sensitive, for each entity, there will be a need to set an access control panel. Which defines what agent needs what, or sees what. And then this speaks to Layer 4
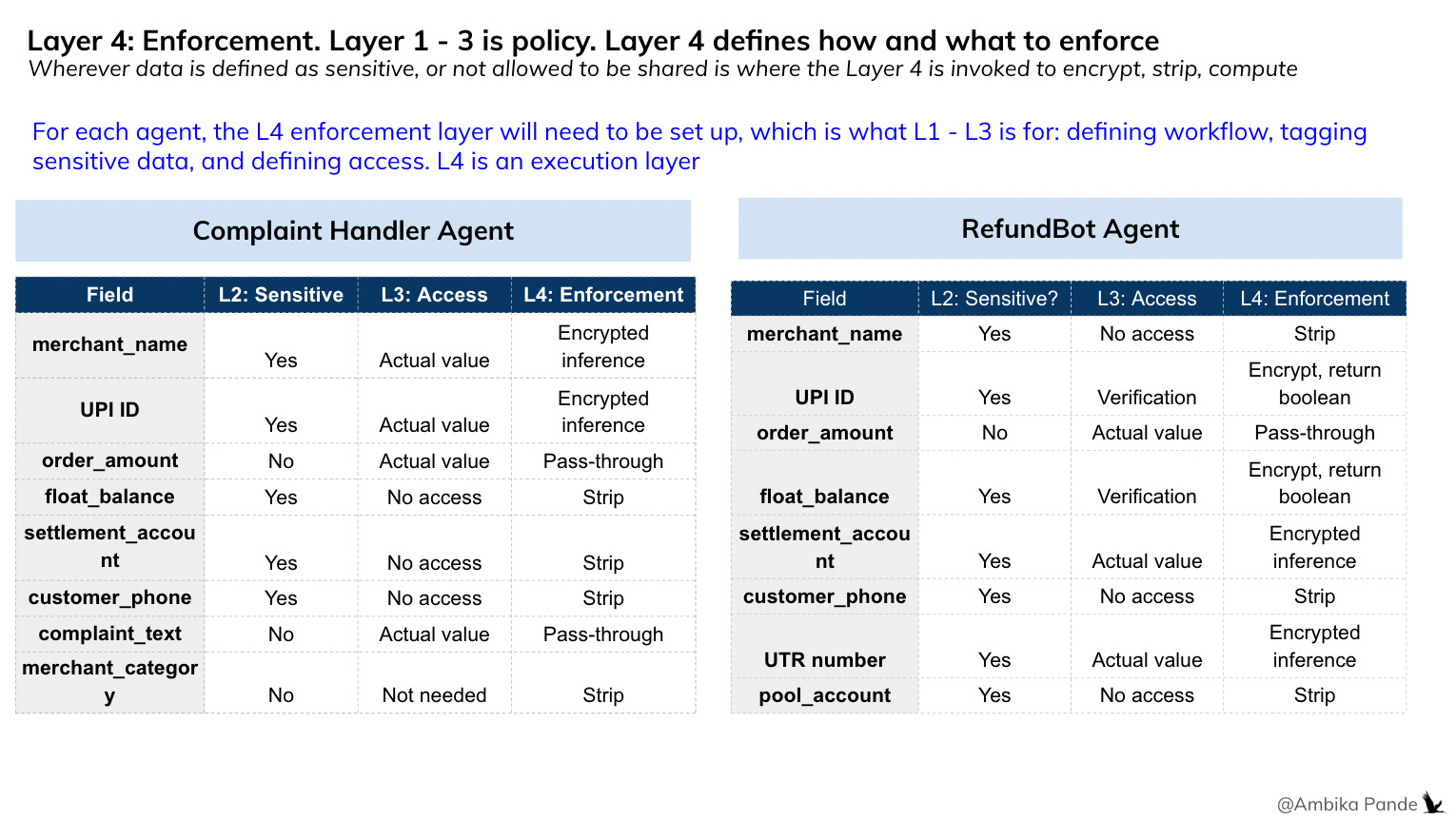
Layer 4: Enforcement of Layers 1 - 3, where encryption and computation layers come in
Layer 4 is the trust layer or the encryption layer (which is what Silence Laboratories builds) that ensures that basis Layer 1, Layer 2, and Layer 3, the system first has visibility of all the data flowing, then is able to define what is sensitive data at Layer 2 and what isn’t, then go to Layer 3 for access control, which is define if the agent needs this data, if it is allowed to access this data, and what output it needs. And then depending on that, layer 4 decides the type of encryption: if it is a verification, or if it is some sort of joint computation, or something else. So based on L2 - if the data is sensitive or not sensitive, and L3, who has access at what step, and what is needed, Layer 4 can provide the necessary encryption
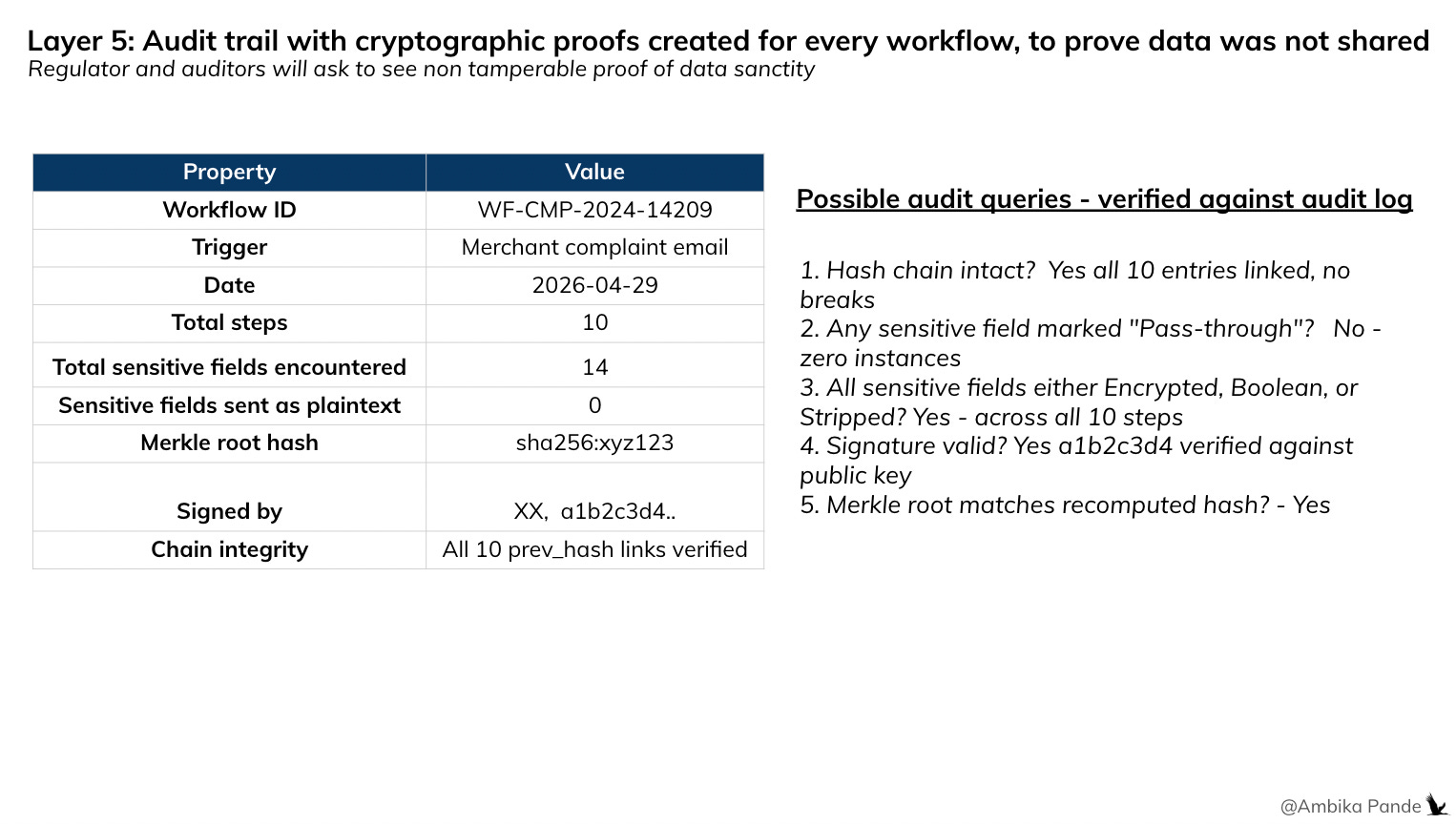
Layer 5: Audit Trail. Proves what happened in Layer 4
This is the audit layer. It actually proves to regulators that what is claimed in Layer 4 happens. So for example, the auditor / regulatory authorities may ask: give me proof that there was no raw merchant data shared with the LLM provider or this external agent on 29th April 2026. How do you prove that?
Ideally, for every workflow execution, the logs need to capture:
Timestamp
Workflow ID
And for each step (Step 1/2/3)
Agent
Action
Fields received
L2 tags applied (what data is sensitive)
L3 tags applied (what can they access)
L4 enforced (compute / replace / stripped)
What was sent
And these need cryptographic proofs that are tamper proof. Regular logs can be tampered with. I actually found an interesting company building for this specific use case: here
So, how would this work in real life?
Well, the below is the workflow that I’ve imagined, very specifically for this refund flow. Earlier, there was plain text that was being shared. Now, basis the context graph, the data type, the access control, the enforcement layer allow plain text passthrough, encrypted computation and boolean / verification shared, joint computation between two parties if negotiation is required, or complete stripping away of sensitive data if it is not required.
A point to note here is that the trust layer application is required to be done by both parties that are communication or collaborating. In the below example, it is not just enough that the Complaint Handler Agent integrates it, there also has to be some endpoint sharing, or integration done by the CRM tool, RefundBot, Complaint Handler LLM to ensure that everyone is speaking the same language.
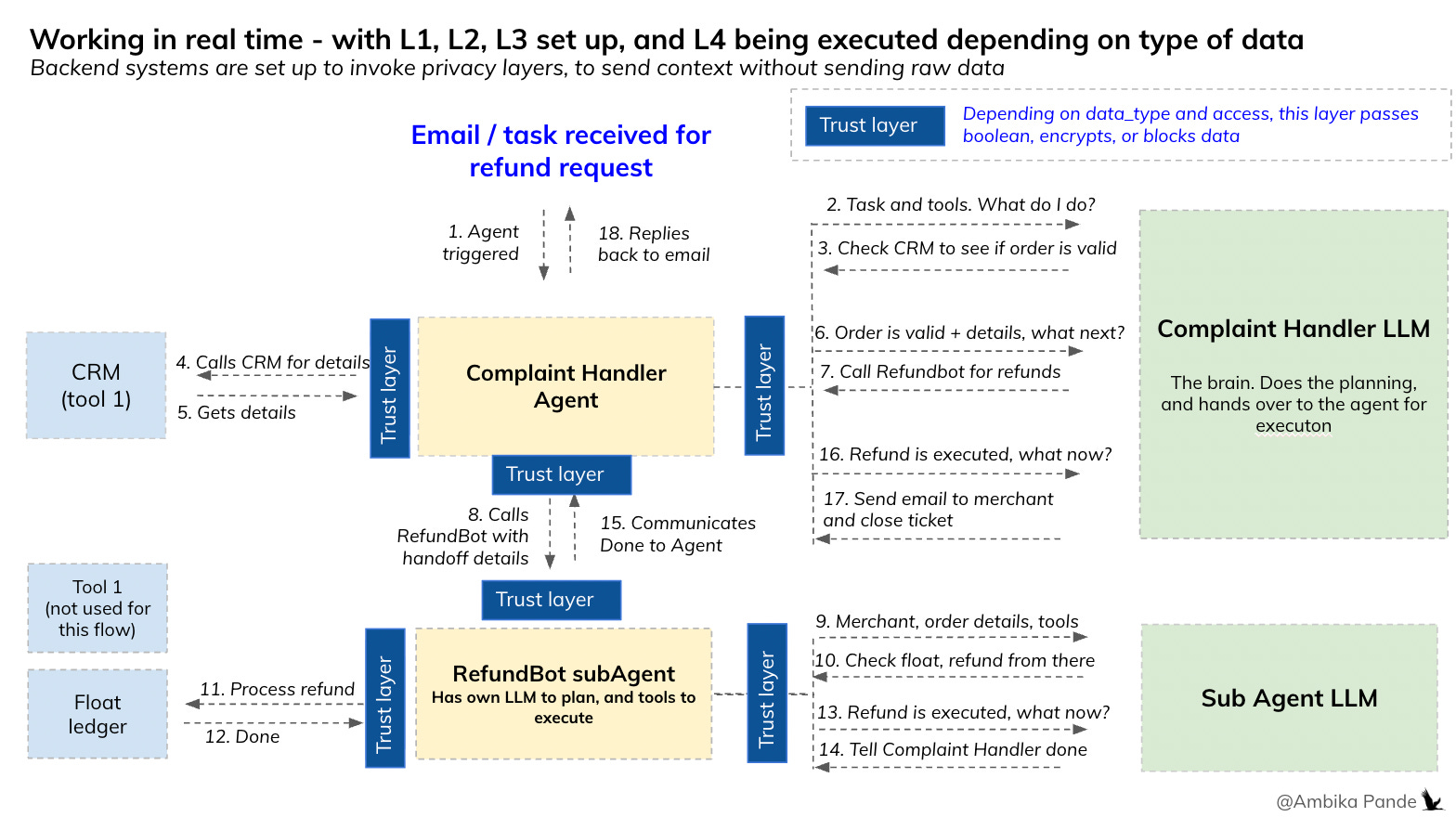
And then, putting it all together, this is what I believe that the organization’s data privacy stack could look like
Context Graph: Set up a context graph template, that can then be reused across workflows
Data Tagging: Tag your data (this is usually already done to some extent, to define what is sensitive, what is the level of sensitivity). This is important, as this will define who can access what, and what type of enforcement is needed
Access Control: Decide who has access to what sort of data, and what they need it for. Example: A refundbot may just need fund amount < x amount verification, not the actual number. The Complaint Handler Agent may just need to know if the merchant exists, not the name and details.
Enforcement Layer: Depending on what agents needs access to what data, the enforcement / trust layer allows pass through of plaintext, encrypts, computes and shares the output for decision making, or strips the data completely
Audit: At each step, hash chaining is implemented so that each step is linked to the previous step, and the logs are tamper evident, and merkel trees for verification.
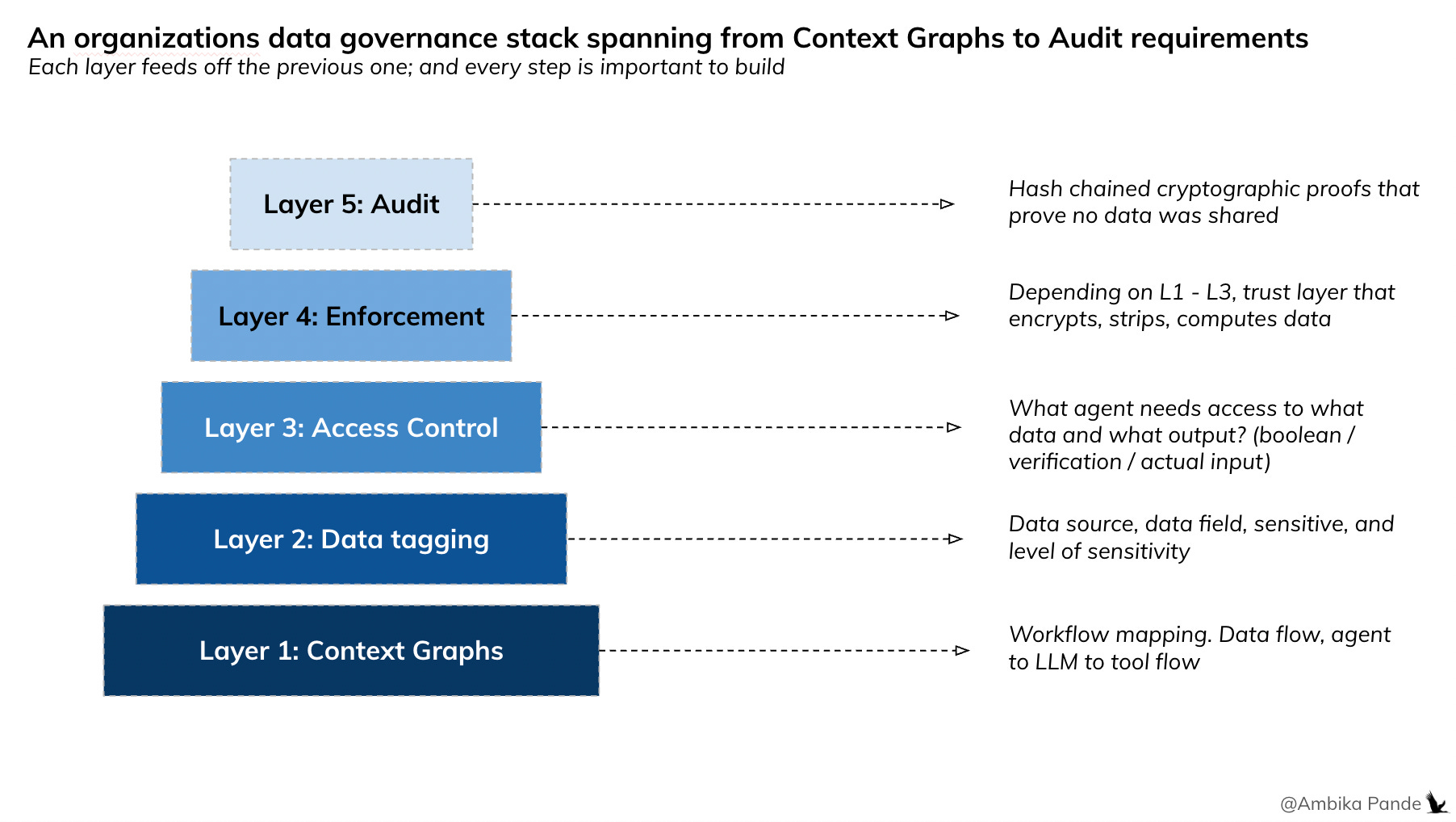
The problem with solving privacy at the foundation layer
There are many ways to solve for privacy and security in multi-agent systems. The mistake most approaches make is solving for it too early, at the context graph, data tagging, or access control level. When you hardcode privacy constraints into your foundational layers:
Workflows become rigid: you can’t reuse the same agent for a different task without reconfiguring access
Tool access gets restricted: agents can only call tools that fit the pre-defined security model
Data sharing gets over-constrained: you strip or block fields that the LLM actually needs, and output quality suffers
The trade-off becomes: security vs. usefulness. And most systems pick security by making the agent dumber.
The layered alternative is what we’ve been discussing here, enforcement happens as a subsequent layer
In an ideal system, privacy and security are not baked into the foundation: they’re layered on top. The foundational layers (context graph, data tagging, access policies) define what exists and who should see what. The enforcement layer decides how and when to invoke trust mechanisms: encryption, compute and replace, and selective disclosure.
This is the same architectural shift that moved software from monolithic to modular. You don’t hardcode business logic into your database schema. You build flexible foundations, then layer decision logic on top.
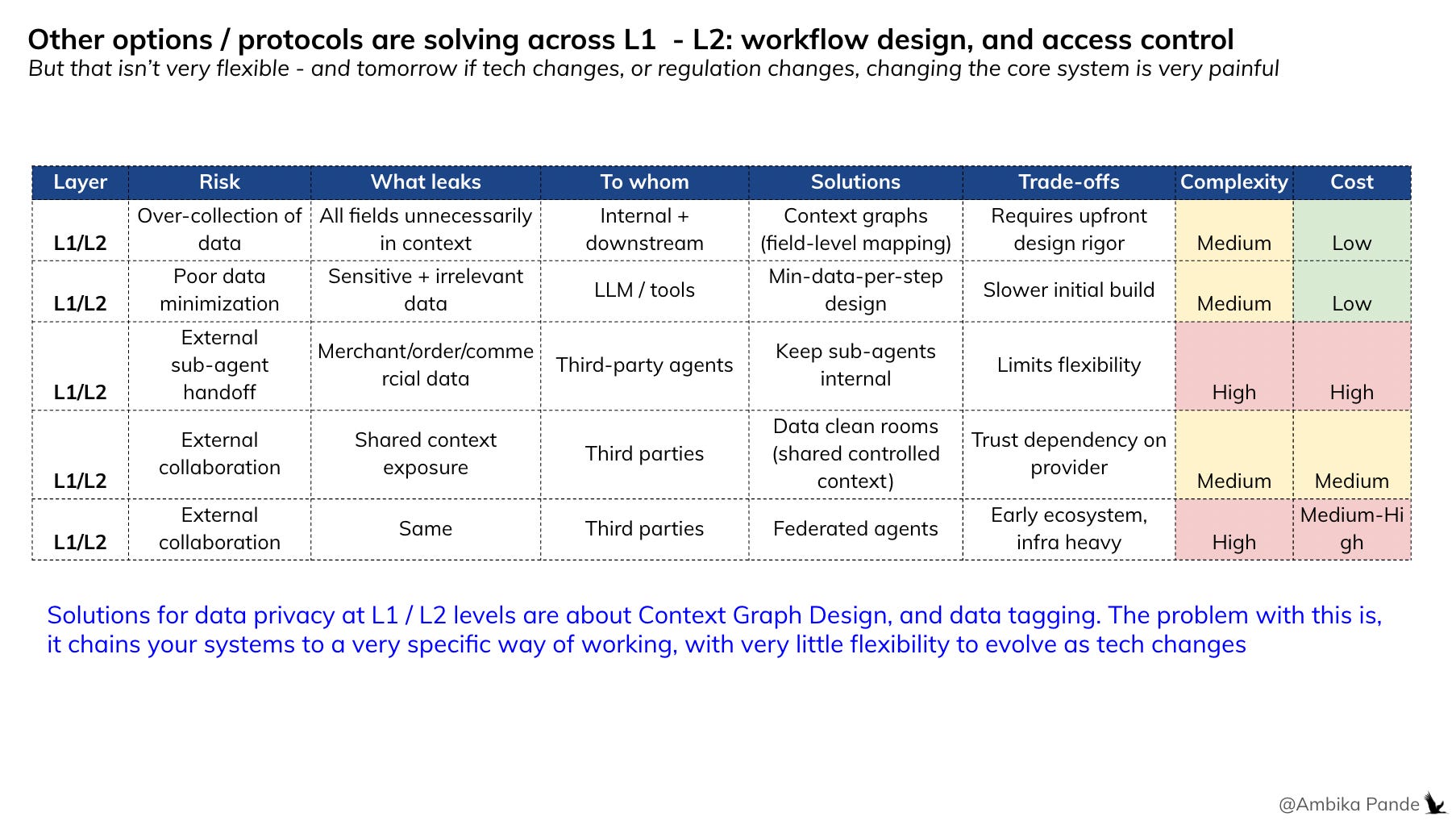
The landscape of solutions today and where they fall short
Across the agent ecosystem, different protocols and approaches are solving for different layers of the problem. Some are essential building blocks. Others create trade-offs that limit what agents can actually do.
What’s needed regardless of solution:
Context graphs: you need to know what data flows where
Data tagging: you need to classify what’s sensitive
Access control: you need policies defining who sees what
These are foundational. Every serious system needs them. They’re the map, and this is required regardless of whatever implementation the org decides to go with, whether it is clean rooms, or shared context, or anything else.
Where approaches diverge and compromise:
Approach 1 : Clean-room architectures
What it does: Restructure the entire data layer to isolate sensitive fields before they enter the system
What it costs: Rigid. Every new workflow requires re-architecting. Doesn’t scale across use cases.
Approach 2: Redaction / masking
What it does: Strip or mask sensitive fields before they reach the LLM
What it costs: The agent makes decisions with incomplete information. Less context = worse output
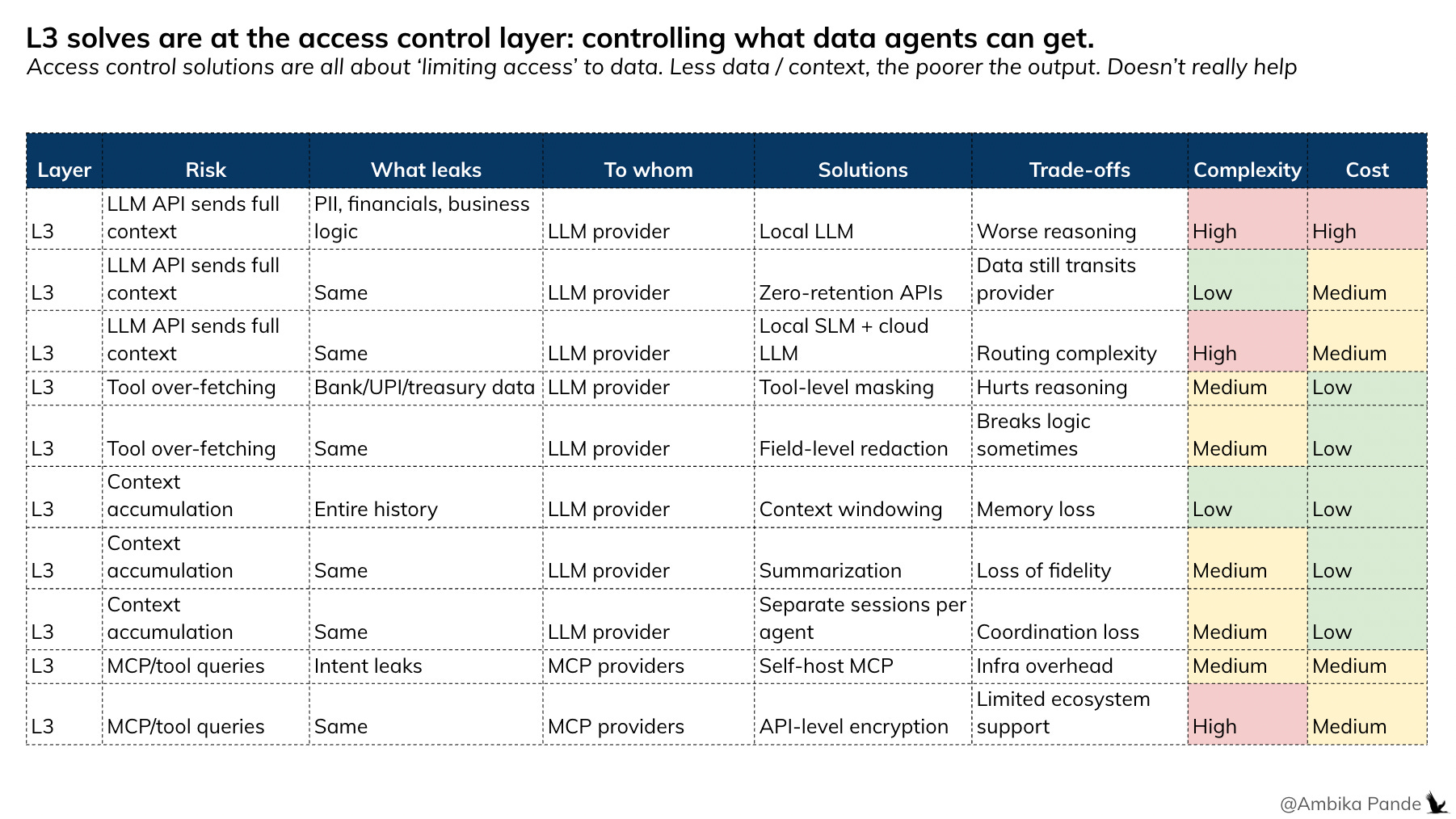
Approach 3: Local LLMs / SLMs
What it does: Keep everything on-premise with smaller models
What it costs: Solves the privacy problem by downgrading the reasoning. You get security at the cost of intelligence.
The common thread: these approaches solve privacy by taking something away: flexibility, context, or model capability. Clean-rooms limit your architecture. Redaction limits your data. Local models limit your reasoning. Each trades output quality for security.
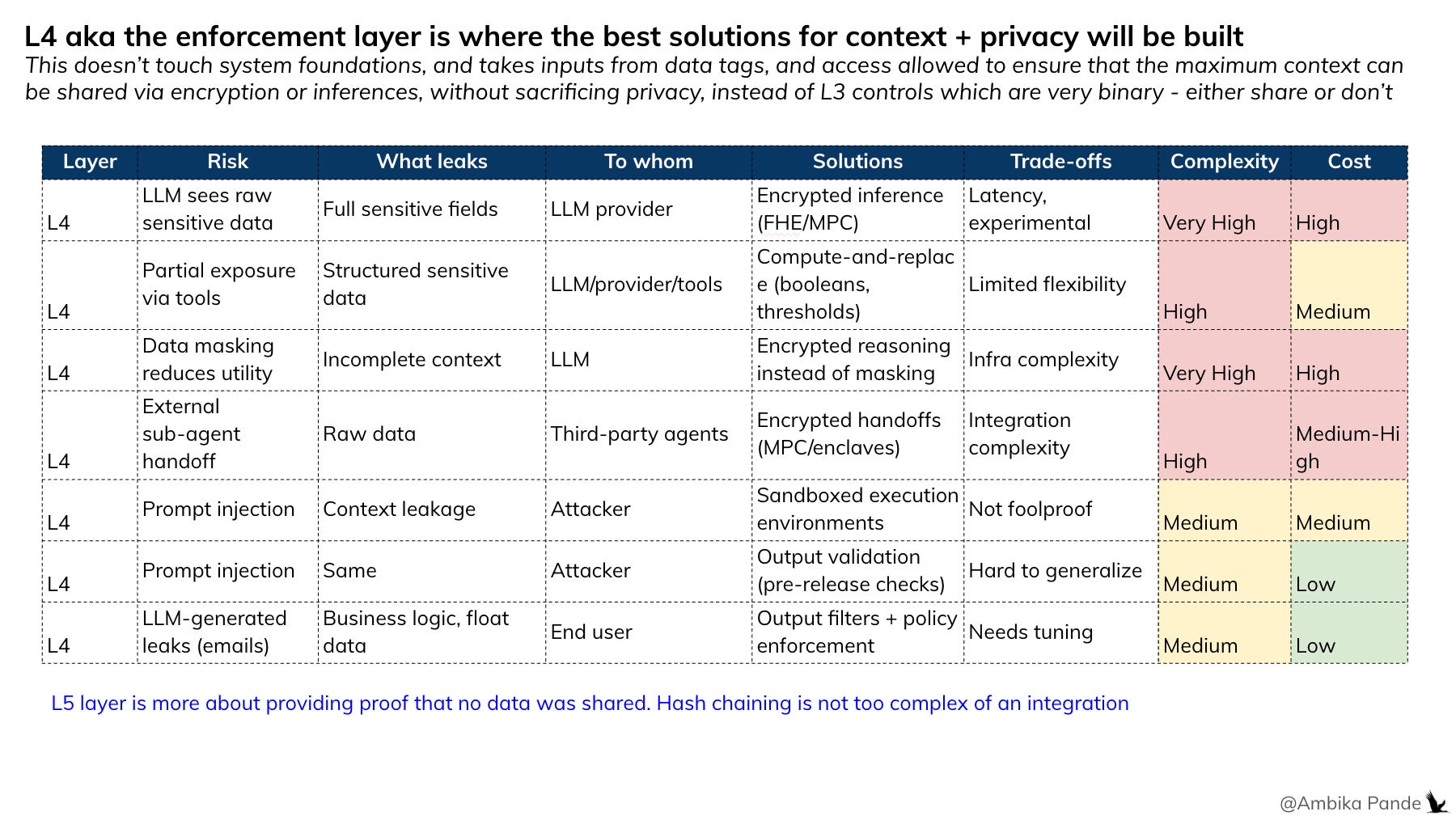
The alternative: Don’t limit the foundation, strip the data or downgrade the model. Let the full context flow through the system, and enforce privacy at the computation layer where the LLM can operate on encrypted data without ever seeing it in the clear. That’s the difference between privacy by restriction and privacy by design.
The Scaling Principle: Define openly but enforce dynamically.
L1–L3 describe the world as it is: what data exists, how sensitive it is, who should access what. These layers are declarative. They don’t block anything. They don’t make runtime decisions. They’re a map, not a wall. L4 is where the decisions happen: at runtime, in context. The enforcement layer looks at the map and decides: encrypt this, reduce that to a boolean, strip this entirely, pass this through. It adapts to the workflow, the agent, the task, and the moment.
This separation is what makes the system scale. The foundation doesn’t need to anticipate every scenario. It just needs to be honest about the data. The logic layer handles the rest. You don’t hardcode business rules into your database. You don’t bake authorization into your API schema. You build flexible foundations and layer intelligence on top. Hardcode privacy at the foundation, and every new workflow needs a new configuration. Every new agent needs a new policy. Every edge case breaks something. Layer it, and the foundation stays stable while the enforcement adapts. New workflow? Same L1–L3. New agent? Add it to L3, L4 figures out the rest. New regulation? Update L4 logic, nothing else changes.
The principle: Open foundations, intelligent enforcement, runtime adaptation. That is what we need to scale agentic systems
A quick prototype I built just to illustrate this point better: here. This shows the e2e flow, from Layer 1 to Layer 5 - setting up a context graph template, tagging data, defining access, and then layering enforcement on top of what Layer 1 and 3 defined. And finally, how to prove what we claim happened in Layer 4.