
[#55] The rise of Small Language Models: Building a wrapper around LLMs is where innovation lies, but what about cost, inbuilt biases and data privacy?
As we build search engines, and AI agents on LLMs, apart from the computation & data, we are also subject to inbuilt biases, and as we become more dependant, these biases could influence our decisions



Some time ago, I had written about LLMs & AI, and the opportunity for innovation. You can check out the article below:
[#52] LLMs and AI: What are the opportunities for growth and innovation?
![[#52] LLMs and AI: What are the opportunities for growth and innovation?](https://substackcdn.com/image/fetch/$s_!Ik_0!,w_280,h_280,c_fill,f_webp,q_auto:good,fl_progressive:steep,g_auto/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F4b519a6e-4097-4538-8a39-db3f9ba7c39e_960x540.png)
With all the buzz around LLMs and AI, what are the actual opportunities for building and investment in this space? There is so much buzz, hype & even jargon around this sector, that a lot of times, its hard to follow, and really make sense of what is actually happening.
And while there is opportunity to innovate, the dependency on LLMs, also means that we are subject to their inbuilt biases. That’s something that Devki Pande (Producer at Applause; author of upcoming The Imitation Englishman published by Bloomsbury), and Chinmay Shah (Software & AI Engineer, Co-Founder, Arrowhead) and I were discussing.
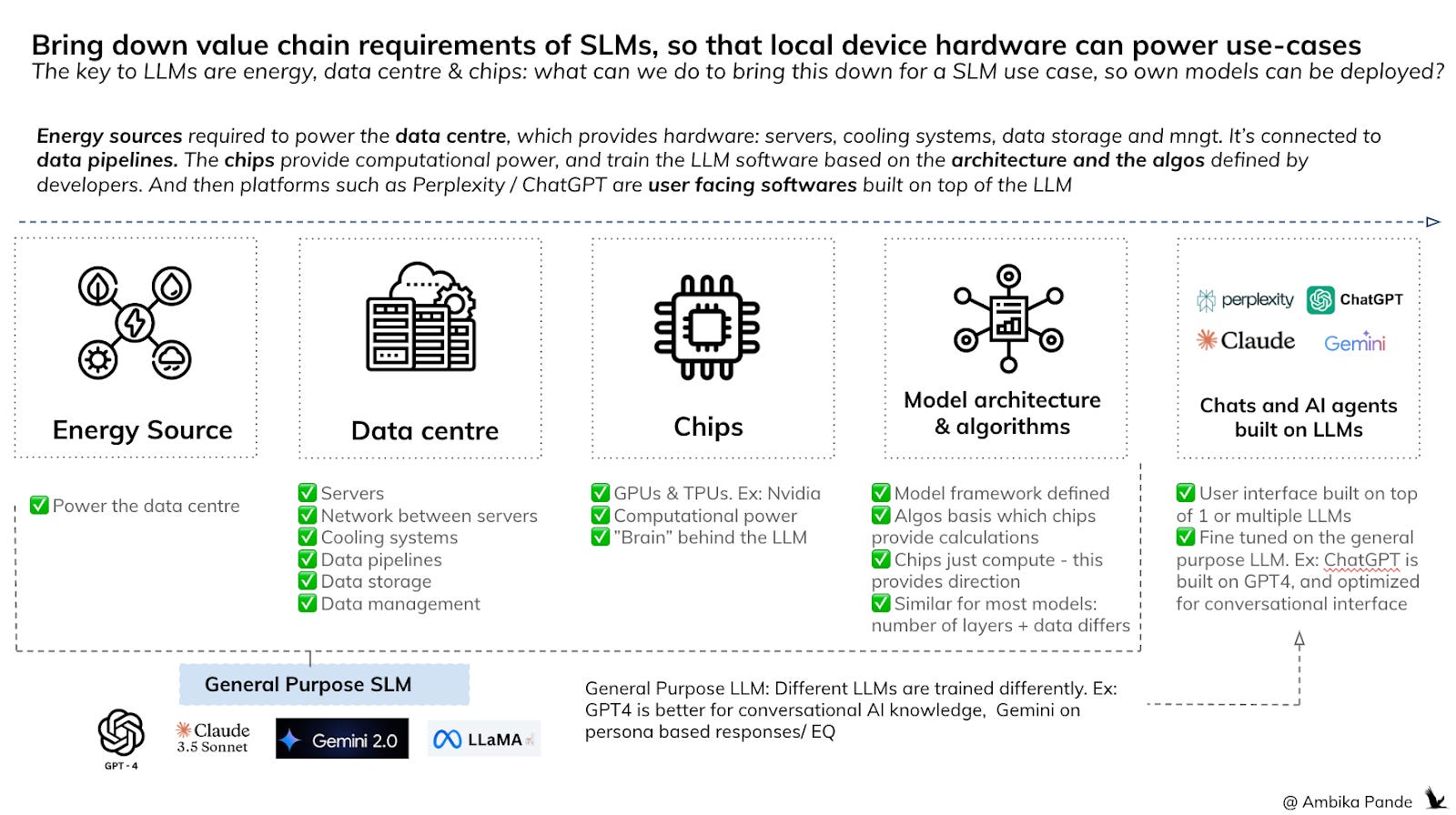
To recap quickly, LLMs are massive models, which have been trained on a large amount of data, and have crazy contextual and computational abilities. How they behave is defined by model architecture, and the chips which are providing the computational power to train it. And of course, the data that they have been trained on. To recap: some of the major LLM models that currently exist in the market are Llama (Meta), GPT (OpenAI), Gemini (Google), Mistral, XAI (invested in by Elon Musk), and Claude (Anthrophic).
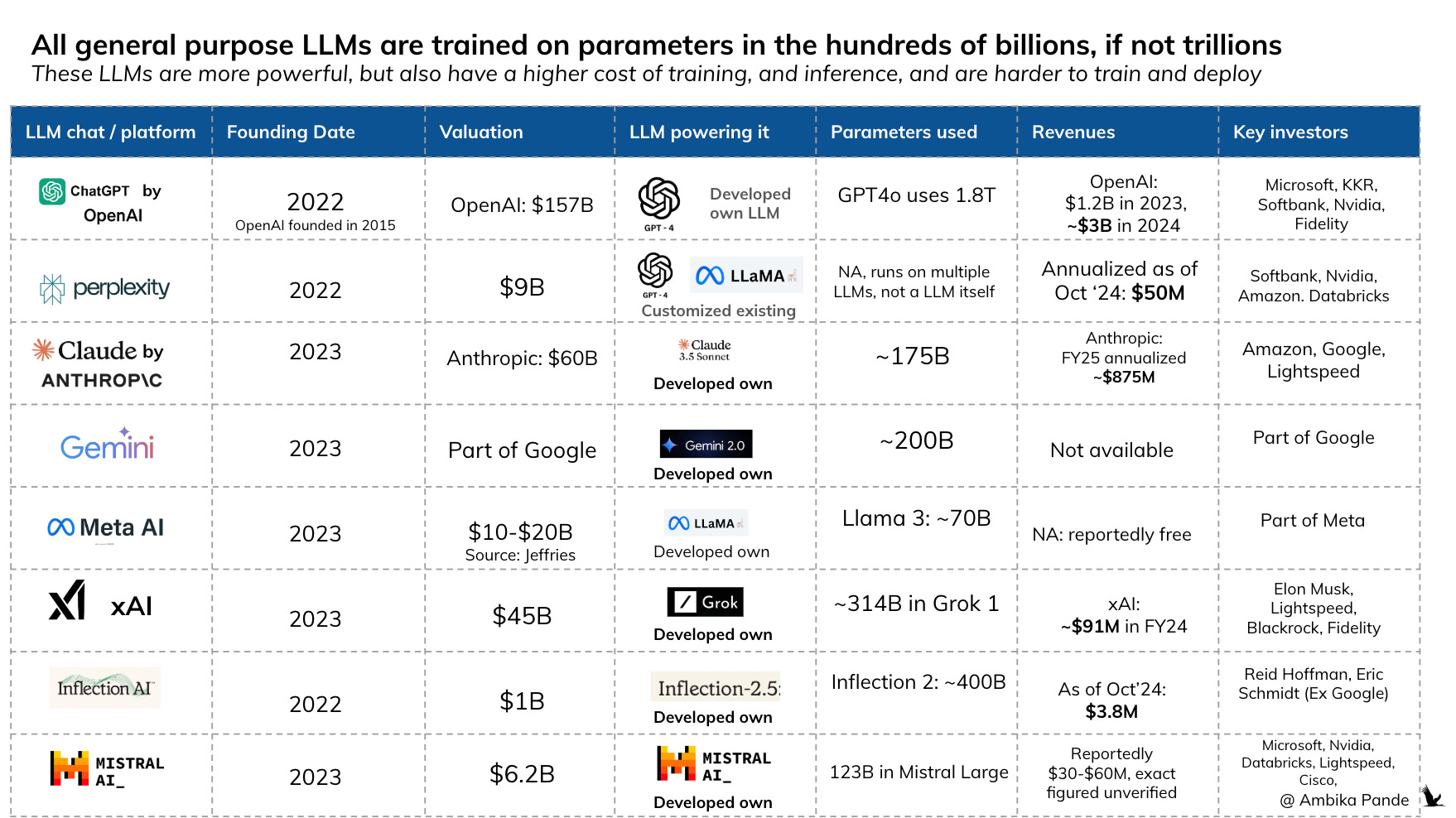
These models are constantly being trained and upgraded. And if you notice, atleast basis the costs needed to train these LLMs, only big tech (your MAANG) companies can invest in building these out. In fact, a lot of these companies are investing across the value chain: investing in energy sources, (nuclear for example), data centres, and chips. And because MAANG companies anyway have their own data plays, they have existing data centres they can leverage to some extent, however, they will need to invest more, as the usage of the models increases (this is the cost of inference, or the cost per query). Which is already happening, as you can see below, all of these players are investing across the value chain.
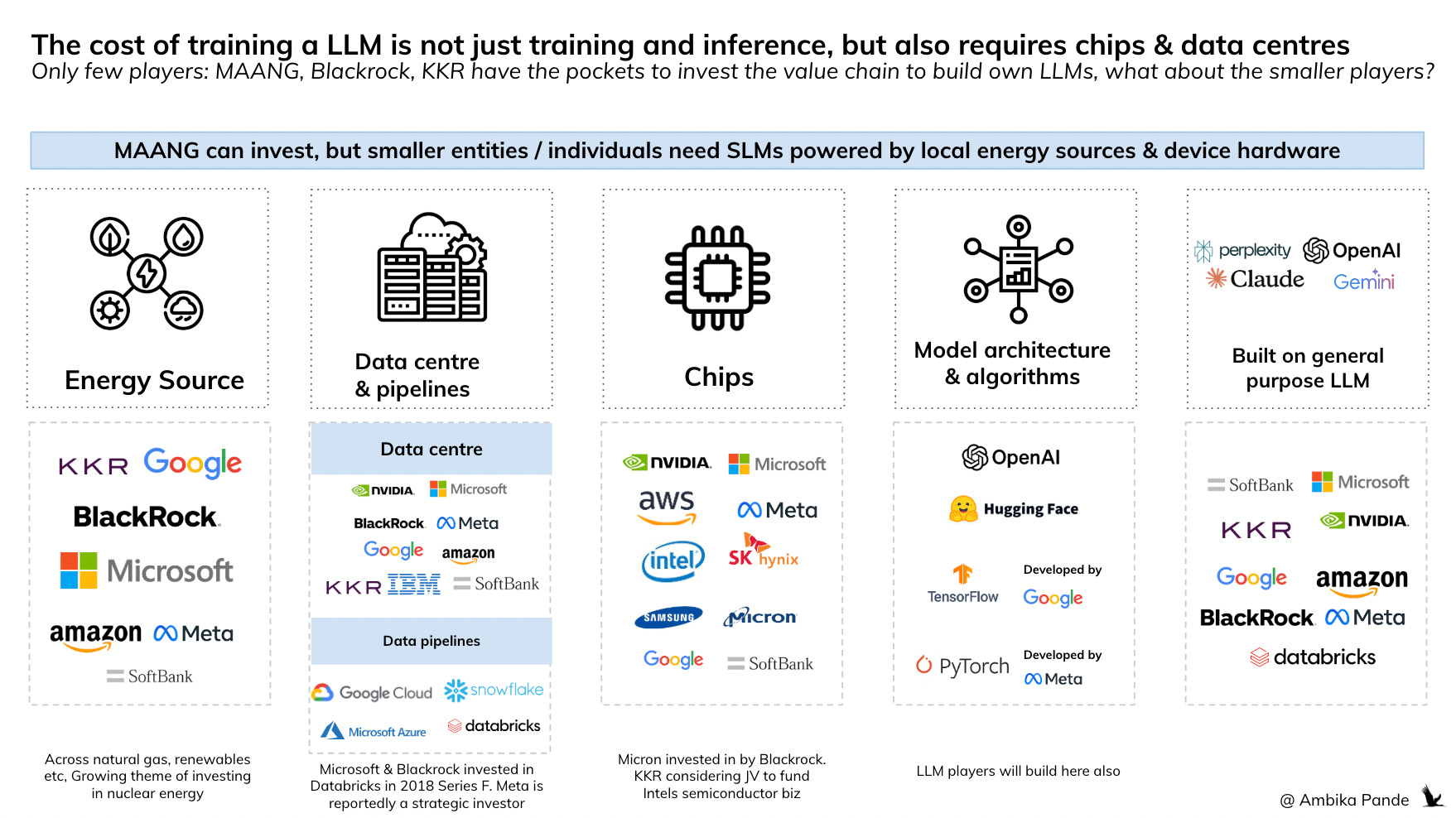
With Deepseek’s new reported costs, which are a fraction of what OpenAI costs are, gives two possibilities: Either companies train their own LLMs, or they use existing ones
Either is a possibility. Costs are one aspect of this, it’s also just the headache of building your own LLM. Even if a company is able to “rent out” data centres, which by the way will come with their own costs, and get access or have enough data to train their models to some % of the computational capability of the general LLMs currently, this may be too much overhead for someone who’s core product is not the LLM, but the products built upon on. Perplexity is a great example: It’s not a LLM, but is a search engine layer built on top of multiple LLMs, and uses LLMs to exponentially augment its capabilities as compared to a regular Google Search.
My own view: Companies will prefer to use existing LLMs, maybe fine tune them a bit for specific use-cases if the use-case in question is more niche.
However, there are questions around Deep Seek misrepresenting its costs:
Multiple questions around Deepseek currently. While their announcement that it was trained at a cost of $6M, and that too as a side project by some hedge fund which wanted to use unused chips, there isn’t information to validate this or not. As a non-expert, my limited perspective is $6M is really low, especially when you look at the $3B training cost that OpenAI will reportedly pay in 2024 (cost of inference being another $4B).
People claim that they have access to way more Nvidia H100 chips than they have claimed, due to import restrictions that Nvidia has on it by the US. They also claim that Deepseek has misrepresented costs, and has not accounted for the $$ spent on “guesswork” and “tinkering around with the model.
Again, this could also be an effort by the West to portray their efforts and models as superior, and explain the valuation of their own companies -> Nvidia etc all have benefited greatly from this. In fact, after Deepseek released its model and the costs associated with it on Jan 20th 2025, Nvidia’s stock dropped by 17%. It was trending at $140 / share, and dropped to ~$118. Now it’s rebounded by a bit.
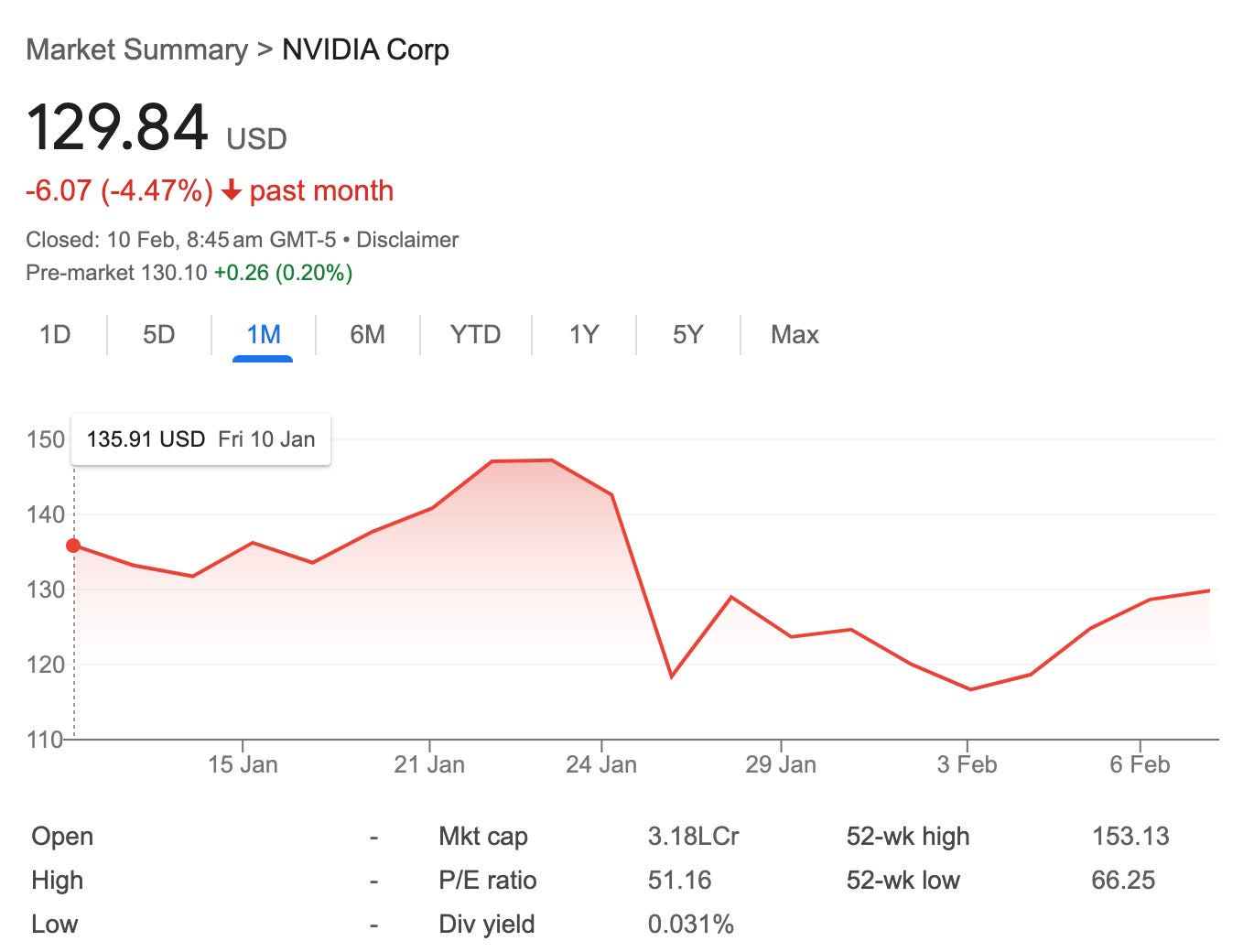
But whatever it is, just going by first principles thinking, and what has happened in the past. LLM will get cheaper to build and maintain. How much cheaper though is the question. Millions are cheaper than billions, but it’s still a lot of money and overhead for a company that wants to build on top of it.
That’s the just cost angle. The issue of biases is separate.
Before we get into biases, it’ll be good to understand why this is a problem:
If I’m using the LLM chat, or a search engine, such as chatGPT on GPT 4o, or perplexity which sits on top of multiple LLMs such as GPT, Mistral and Llama, then while it may work fine for basic tasks, simple things such as asking to draft a document structure, maybe research, and other things. But when we start using it as a “second brain,” and in automating decision making, that is where the problem lies. As we are more dependent on AI Agents & Search Engines built on top of LLMs, we are also subject to their biases. A great example is Deepseek, developed by China, vs a GPT 4o.
I was playing around with it over the weekend, and while I know this has been pointed out in multiple forums on Linkedin, and on Reddit, it’s a great example of the biases that lie within a model. And who knows what else is lurking? It’s impossible to test everything, there are always edge cases that escape us.
Deep Seek response was very China biased: when prompted about the status of Tibet and Arunachal Pradesh, responds in China’s favour. When prompted further, it gives “server is busy” message.
Note: Tibet considers itself independent, but China considers it a part of China. With regards to Arunachal Pradesh, it is recognized internationally as a part of India, but China considers it a part of China.
Chat GPT response: Gives more perspective on both issues. However it’s worth noting that in this case, the territory is not disputed by the US, and so OpenAI has less cause for bias. You can check out the difference in responses below, or even go check it out yourself.

This isn’t a problem today, but as our dependency on LLMs grows, it will be. More of these biases will creep into our everyday lives
AI Agents, and using LLMs in every day work is still fairly new, and has a long way to go before it evolves. The problem here is one of responsibility. If LLMs are the foundation that everything is built on, I would actually say that it should NOT be privately funded, by big tech, and the big VCs of the world. It’s a public good, like UPI, or the DPI initiative that India has set up. But then there’s another issue here. UPI are just rails, which define a way & expose APIs for smoother payments. The infra being used to actually transfer the money is what has already existed: IMPS. LLMs, even if created by the government, will have the government’s bias built in. Take an example of the current US government: which is trending towards being more right wing. Different parties and leaders have different fundamental principles that they live by, which could be inbuilt into these LLMs. And that’s the problem with privately funded LLMs as well. At the end of the day, for the user, it’s a black box. I’m inputting something, and I’m getting an output. I don’t know how it’s being trained.
Prime Minister Modi highlighted this at the Paris AI Summit. When LLMs are asked to generate images of left handed writers, they still output images of right handed examples, as right handed examples dominate the training data.
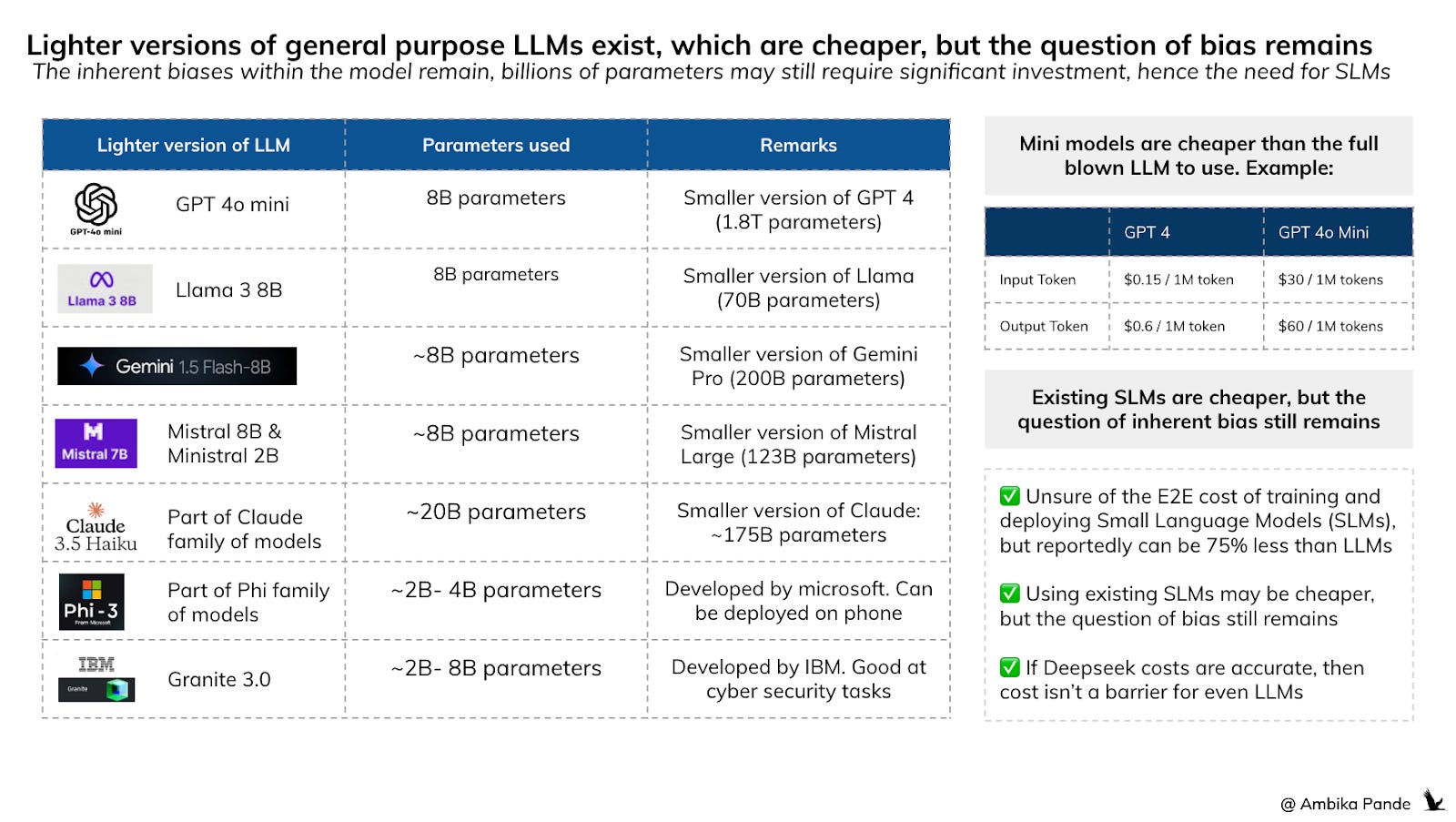
And as more dependency comes onto these AI Agents, they’ll take decisions, with the underlying bias in the LLM as an input. So then the long term solution & the opportunity seems to be: mini LLMs or small language models (SLMs), that can be deployed locally. And instead of using billions of parameters, (GPT 4o has more than 1.8 Trillion parameters. There is also a smaller version available: GPT 4o mini, which uses 8 Billion parameters, which is also how many LLama’s mini version - the Llama 3 8B has) they use millions.
And maybe a version of this is the solution, and the opportunity.
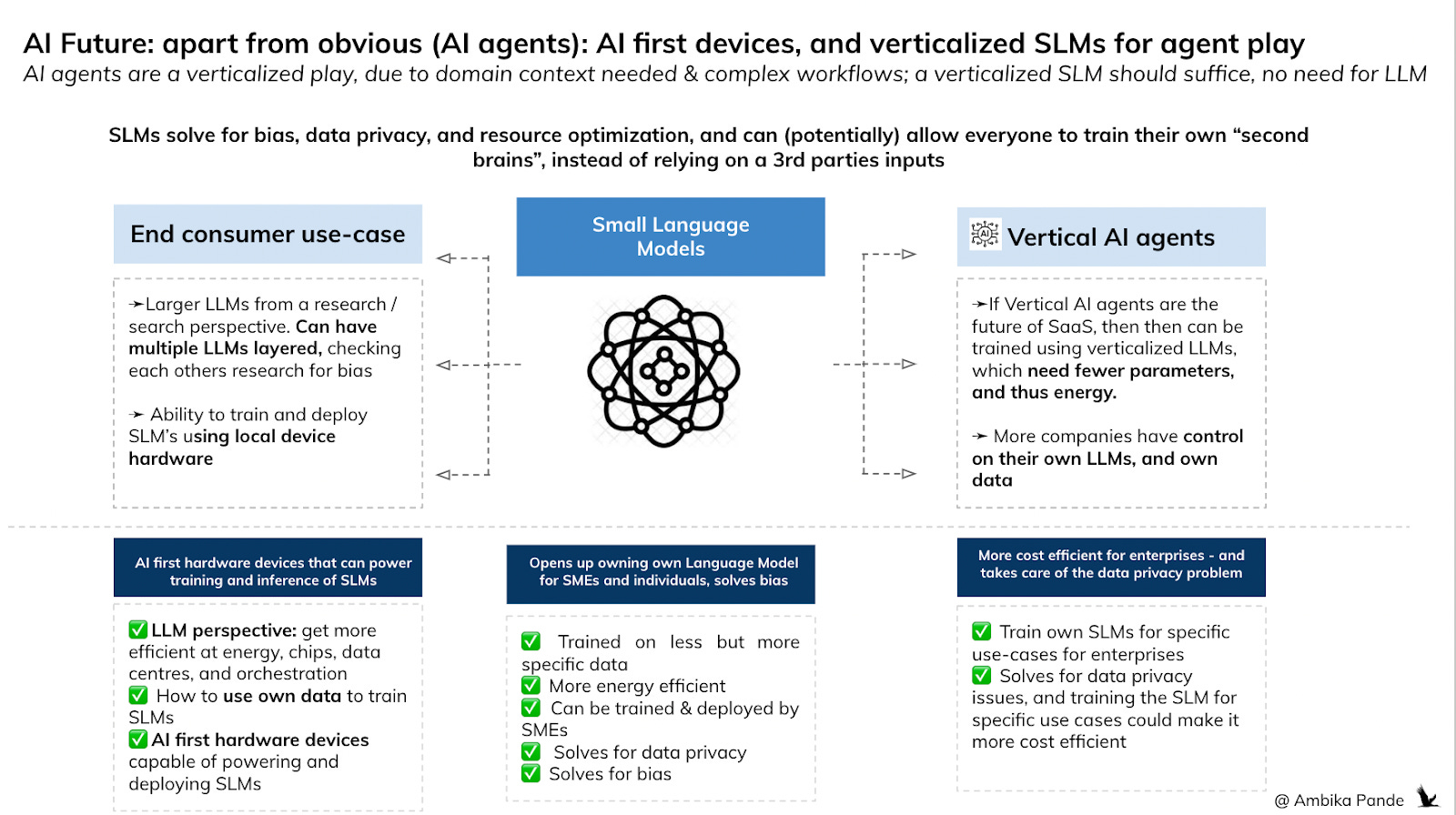
As AI agents as a use-case grows, Verticalized SLMs could be the solution
So what are AI agents? I covered this a little bit in my previous article, but think of them as software that can do complex tasks similar to how a human does. What does a human do? To execute something, a human breaks down the task into multiple sub-tasks, which could be getting the data from a database, doing some analysis on it. If the analysis is incomplete then maybe double check the data using another resource, maybe do some market research. And then basis the data, execute the remainder of the tasks using tools, which could be for sales / marketing or anything else. That is exactly what an AI agent does. The LLM here is used to translate the user query & break it down into multiple tasks. It also creates some sort of action plan, and constantly provides context and computational strength for any task that requires additional calculations.
For a general AI agent, obviously it needs to be prepared for a lot of different use cases, and this is maybe where a general purpose LLM comes into the picture. It has a lot of different use cases and queries it needs to handle, which may be tough for a SLM to manage. But for a verticalized AI agent, for specific tasks, a SLM may suffice.
Example: A verticalized AI Agent may be used to create marketing campaigns. It knows that that is the end goal. And there are pre-programmed workflows within it: Example, get the most recent data, set up a campaign in the Ads Manager, and monitor the outcome. Where the LLM comes in, is so that the AI agent can intelligently handle unforeseen / dynamic circumstances. Ex: What if the data is not updated in the database? What if the most recent data shows that we need to target a location that previously has not been focused on? What if the budget approval has changed? An AI Agent combines these specific pre-set workflows, with dynamic decision making.
Now coming to SLMs: For verticalized agents, who work in specific domains, a SLM may be enough to power the use-cases:
And hence, my view. As costs go down, and dependency on AI / LLM increases, companies may see value in building and deploying their own LLMs. It also helps with data privacy. Take fintech as an example. Everyday, fintech, and companies in the financial sector deal with a lot of data. Even internally, you have tools that interact with this data. Right now, for folks building public tools: You’re sharing data with the LLM through APIs, but then the LLM can use this data. And while every company claims that they have stringent privacy controls, you really never know how this data is being stored & used.
For companies that deal with personal / private data, and even generally (why would you want to expose your data to an external entity), and who do want to use LLMs to enhance productivity, a SLM may be the way to go.
Just a point to note: when I talk about Small Language Models here, I don’t mean a LLM, that has been distilled, and a SLM version created out of it, such as GPT 4o mini, being a version of GPT 4. I mean models that have been trained on fewer parameters from scratch, for a specific vertical / segment, instead of a smaller model leveraging outputs from the parent LLM
In the future, this is maybe another opportunity for innovation. Start-ups that allow you to use your data, and train and deploy SLMs on your own hardware. This will still cost money, no doubt. But reports say that SLMs can further bring down the cost of LLMs by 75%. And maybe this gets to a point, where this is like your AI cost, like how companies have a data cost, or a subscription cost of using a tool. It’ll also force us to innovate on being more resource efficient: instead of using large data centres which need millions and billions of dollars of investment, we need to be at costs where companies, and maybe even individuals can afford it
Does this remove the need for a general purpose LLM? Probably not.
General purpose LLMs will still be around. But more from a use case, where a consumer is using it for general research, search engines, document drafting, queries etc. And more general cases, where there is no private data being shared: chat bots, answering general queries, content creation etc, all are powerful use-cases on their own. But not really to build AI agents and automate workflows on, when private data is involved.
My view: The bias of using general purpose LLMs with inherent biases built in is still pretty scary. The Social Dilemma, an excellent documentary that was released on Netflix in 2020 says this well. The more you see / hear of something, the more probable it is that it will impact your worldview, and that’s step 1 to be radicalized. Of course, I’m jumping the gun here. But as we get more dependent on LLMs to do our thinking for us, it’s like depending on another brain, and allowing it to influence how we think. We can build in layers to control this to some extent: example: multiple LLMs checking each other’s work to get to the final output. But that is trying to combat one bias with another.
What about the LLM is built as a public good: kind of like UPI?
LLMs are the foundation upon which the future is being built. Why can we not see it as a public good, like UPI? (of course, here, what we would need to solve is pricing). But can India create a public LLM, which isn’t privately funded, which then can be used for general use cases? How do you prevent biases here as well is the question. Take Deepseek for ex. But at least the case with a Public LLM is, that it is not privately funded, and subject to the privatized whim.
This is already being explored under the IndiaAI mission: the Ministry of Electronics and Information Technology has opened up sending in proposals to build a sovereign AI model for India. In fact, Genloop is working on exactly this: a India specific compliance LLM, trained with indian cultural history, context, policy, sourced from domestic websites, parliament proceedings, open source datasets, newspapers, cinema, and so on.
Potential future applications of LLMs such as Neuralink further support the need for having unbiased LLMs. But that’s very futuristic, and the ethical and moral issues are separate. But the point I’m trying to make here is one of dependency. If we’re this dependent on a technology that has the ability to “think” it’s a cause for concern.Not to mention the data privacy issues, and the potential for manipulation.
And hence the need for mini / small LLMs that can be trained and deployed at a SME, if not an individual’s level. We already have local models of Llama that we can download on our devices (it’s powered by our GPUs and device hardware), which helps circumvent privacy concerns. But this doesn’t remove the inherent biases. And the power required for model inference could be more than what the device is used to.
So here’s what I see as possible opportunities to innovate, and structure as AI grows:
1) Optimizations in the general purpose LLM:
1. LLMs: Optimizing the current LLMs that exist, and coming out with new versions. Example: GPT 3, GPT 3.5, GPT 4 and so on
2. LLM orchestration: (goes to managing multiple LLMs and resource efficiency with chips and data centres when multiple LLMs are deployed)
3. Data centres / chips / energy etc: How can we be more efficient. Nuclear energy is one area of innovation, with countries investing in small modular reactors.
4. Fine tune and deploy existing LLMs: Offering this as a service
2) Use cases built on top of general purpose LLMs
1. Search engines: Such as perplexity, which is not a LLM, but leverages multiple LLMs, such as GPT, Claude, Mistral, Grok, & Llama
2. AI Agents / workflows: AI agents built on top of LLMs (this is an obvious one and where we are already). The value of these AI agents will depend on: a) the use case b) the complexity of the task, which comes from subject matter expertise, interactions with multiple tools, and multiple steps in the workflow. And hence, verticalization is where this seems to be headed. Ex: people have domain experience, that make them more suited to a task versus another. Same logic goes with agents.
3) Opportunity to build for SLMs
1. Ability to train and deploy SLMs at a SME and individual level for data privacy and bias removal. This can then also be used by orgs for specific use cases, for verticalized AI agents. Example: I want to use AI agents for specific tasks in my org. I can train, and deploy a SLM, keeping those tasks in mind. I don’t have to share my data with an external LLM, I don’t have to be subject to external biases, and this becomes my “SaaS cost”.
2. AI first devices: As we bring the computational power of Language Models to the public, to make it accessible, they need to be optimized so that they can run on local hardware. Of course, the key is that these SLMs cannot also be so powerful that they disrupt the entire energy grid. But innovations around smaller, more powerful devices, with hardware and chips capable of running local LLMs while in parallel executing other tasks. There are already softwares such as ONNX runtime that help to do this exactly. This isn’t just a software play. It’s also a hardware one.
What’s key to remember is that while we build on LLMs and AI, the question of data privacy and bias becomes even more important. And checks and balances need to be built into each level. OpenAI reportedly trained its models on publicly available data, without explicit consent from the user. There have been multiple cases where LLMs have disclosed sensitive data (both at a customer and a business level), which has led to instances of data leakage.
4) Public LLMs
As I mentioned, the Ministry of Electronics & Information Technology of India, has started inviting proposals for this. Companies such as Genloop are building India specific LLMs, with India political & cultural context.
But I’m still on the fence about how this will play out. On one hand, better a sovereign model than a foreign model. But then there is a reverse bias here, towards India. And as we build models, and use these models as foundation of research, I don’t want my view being coloured by the governments principles (Like the Social Dilemma example I mentioned earlier). There’s already an example of this: Whatsapp forwards. The countless whatsapp forwards spreading misinformation and biased news, has succeeded in radicalising millions of people in India.
But since we’re still early, it’s better we build in structures to combat bias and data privacy now, instead of playing catch up in the future.
 | A guest post by
|
 | A guest post by
|
LLMs can work with custom knowledgebase. Bedrock has the concept of a knowledgebase that can work with a set of generic LLM. You can formulate custom knowledge vectors that can modify how chatgpt responds to queries.
Do these knowledgebases provide enough functionality that customizes the LLM responses for the use cases needed and obviates the need to train an SLM ? This is a question not a statement..