
[#52] LLMs and AI: What are the opportunities for growth and innovation?
Ever since ChatGPT came into the picture, LLMs have been touted to power the next wave of disruption. But what is needed for this to be a reality?



With all the buzz around LLMs and AI, what are the actual opportunities for building and investment in this space? There is so much buzz, hype & even jargon around this sector, that a lot of times, its hard to follow, and really make sense of what is actually happening.
This is something Aparna (Sustainability Consultant @ Accenture), Chinmay (Software & AI Engineer, Co-Founder, Arrowhead) & I were discussing.
The big story over the last 2-3 years has been the rise of AI. The hype started when ChatGPT appeared on the scene. Which then led to the worldwide focus on AI: with other LLM-powered applications such as Claude, Mistral, Llama, Perplexity, and Gemini being developed, since no one wanted to be left behind in the LLM & AI race. And that led to the buzz around the potential of building on top these LLMs, and the opportunity to integrate AI with everything: new startups sprouted up, which essentially created around chatGPT for specific use-cases. Now of course, the new AI powered tool that is expected to power the next wave of disruption are AI agents.
But first things first: What is a LLM?
Simply put, an LLM is a large language model that is designed to generate and analyze human language. Think of it as an AI model that has seen a large amount of data: which is usually text but now also includes images, videos, or anything else. It is then, through pattern recognition, and analysis, able to generate answers / responses / translation based on user input. Technically, current LLMs are deep learning models based on transformer architecture but with billions of parameters.
These are different from AI agents, which are powered by LLMs. Essentially they use software to perform tasks for users: goals, criteria for execution etc are defined by human users. An AI agent uses a LLM to understand input, do analysis, so that decisions can then be made, and then also interacts with tools(software) to execute the necessary tasks.

ChatGPT is more like an application on top of GPT4, not a fine tuned model.
There’s a lot of work that goes into powering the LLM. The key to all of these are data centres & chips (and that’s the reason for NVIDIA market cap passing $1T, and other companies making their own chip based plays).
Below is a view of what the value chain looks like for LLMs, and applications using LLMs to power their functionality.
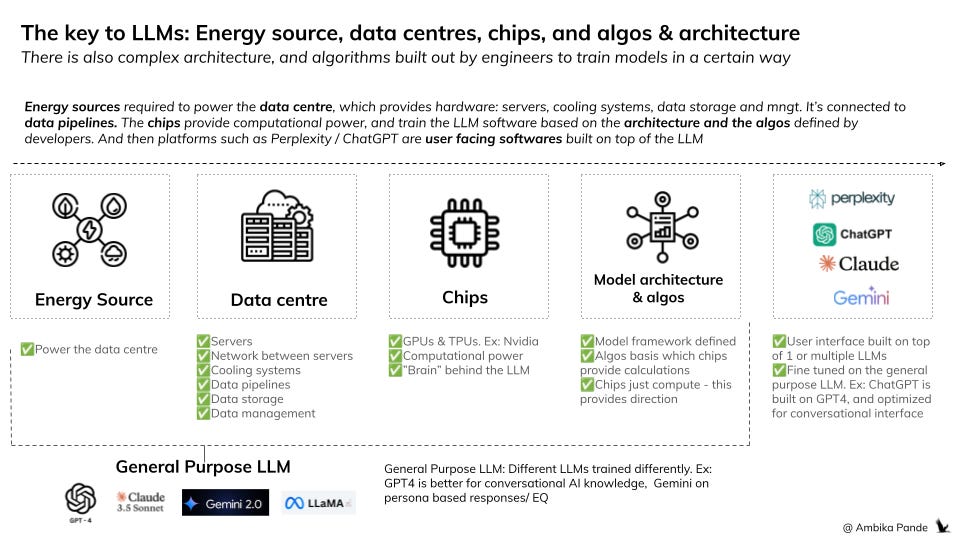
The value chain that goes into building LLMs
So. In very simple terms:
1. The data centre hosts the hardware & servers that run on the chips (GPUs). The chips are used to perform the calculations during the training and inference phase of LLMs. It also provides power access - these data centres need access to large amounts of electricity to power the calculations being done. (other pieces such as cooling centres, data storage & management etc. also sit here). All your big tech players are investing here or already have them: Amazon, Meta, Google & Microsoft. And also PE giants, such as KKR & Softbank.
2. Chips: The chips here (the GPUs and the TPUs) are the “brains” of the servers. They are what perform the calculations and the processing on the data sets to train the model. The big player here is Nvidia, but after seeing the cost of chips, a lot of players are doubling down on their custom chips: AWS Titron, Meta (Artemis), Google (TPUs). Chips play in a role in the training of the model and execution. The roles of chips in different stages of the model execution is below:
a. During training, based on the model architecture, they’re performing logic operations, and training the model, looking at the output, and then adjusting the model accordingly. Which continues until the model is trained, and the structure / rules / how the model operates is set. This usually requires more computational energy.
b. During inference (query execution): After the model is trained, then the chips power the execution of the query based on the pre-defined structure & patterns that were set during training. This requires less computational energy, its more cost effective.
But here’s a question: how do the chips know what to calculate, how to train the model?
That’s where training algorithms and model architecture comes in. Developers define the model architecture & algos basis which the chips perform the calculations on the dataset to train the model. Tensorflow (by Google) and Pytorch (by Meta) are some players that operate here.
Training data: This is shared with the data centre through pipelines, and has to be pre-processed to the model’s requirements before being used. Example: It has to be tokenized, cleaned, and labelled. You cannot just input any data into the data center and expect the chips to perform calculations on it. Databricks, Google Cloud, Snowflake are all examples of data pipelines.
Basis what is defined here is how the chips perform calculations on the data inputted to train the model.
If we look at the key players in this space, the same players are building LLMs and investing across the value chain: almost every player is present in some form in each step
Here’s something that’s interesting. A lot of investors have invested across platforms: Example, Nvidia has invested in both OpenAI and perplexity, while Amazon has invested in Perplexity and Claude. Multiple players are invested in multiple LLMs. Even though they’ve built their own. You can check out the table below for key investors across LLMs.

Softbank, Nvidia, Amazon, Microsoft & Google are all investing across LLMs.
1. Microsoft obviously has its Copilot LLM chat, which is powered by GPT4, and is invested in OpenAI. But its also invested in Mistral AI, which is a company based out of France, which has built a LLM model.
2. Nvidia is invested in OpenAI, Perplexity, & Mistral AI, but I actually expect Nvidia to invest across more LLMs, for them, the more LLMs are running, the better it is for their business, since mostly all these LLMs are trained on Nvidia GPUs (although there are now customized chips coming up, and existing players are doubling down on their investment in their own chips)
3. Google: Google has built Gemini, but its invested in Anthrophic, the parent company of Claude.
4. And then of course you’ve got your Softbanks, Fidelity, Blackrocks, and KKRs of the world, from a PE / VC perspective, but them hedging their bets makes sense
What is also interesting is if you look at the players in the value chain. The same investors who are invested across LLMs, are investing in different parts of the value chain, and some of them, in each other. It’s like a house of cards!
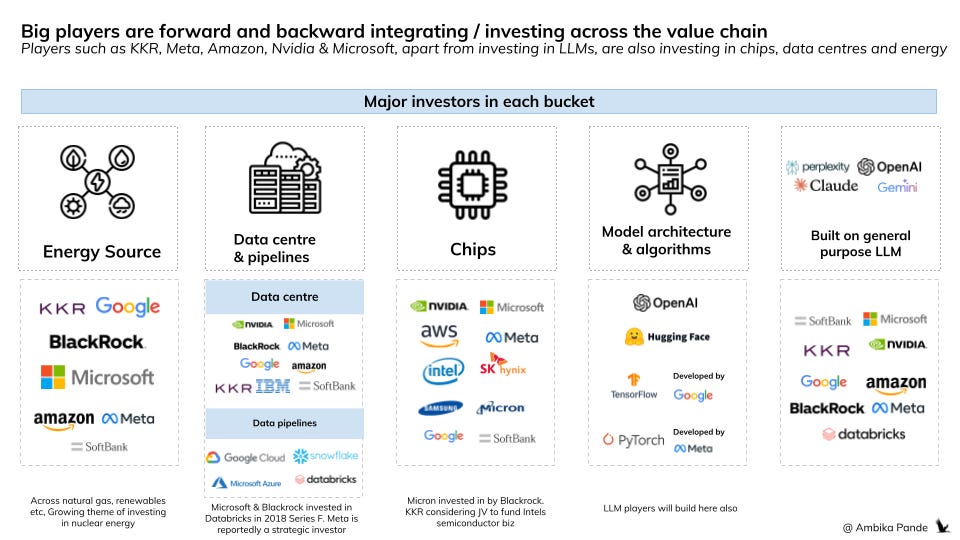
KKR is investing in data centres, it's also invested in OpenAI, (LLM) and Databricks. It’s also reportedly considering a JV to invest in Intel’s chip business
Databricks is invested in Perplexity. Databricks is a prominent data intelligence player, it helps process, analyze and visualize data. Both Microsoft & Blackrock are invested here, along with Nvidia and Meta.
Google, Meta, Amazon, Microsoft are investing in everything: From energy sources to power the data centres, to the data centres themselves, to chips, and of course the LLMs & LLM chats.
OpenAI will reportedly spend $7B to train new models, and run the existing ones in FY25.
Here is where we start asking questions about sustainability.
There are 2 major cost heads. Let’s take OpenAI as an example.
Cost of training: 1 time cost of training the model, which includes the GPU cost, and pre-processing the data, adding training labels, etc. - OpenAI reportedly spends around $100,000 per day to run its services such as ChatGPT. This is ~$4B per year.
Cost of inference. This is the cost of each request. Each user request needs the entire query to be run through the model. Basically running a GPU server 24x7 to serve these requests [Note: can turn off these GPUs if you don’t have enough volume and add more GPUs if you have a lot of requests]. Reportedly they’ll spend ~$3B this year to do so.
So before we start jumping around and start screaming about OpenAI making $3B of revenue in 2024, look at the costs. They’ll be $4-5B in losses. So that’s one question on the sustainability of LLMs. We’re investing all this money, and they’re making billions of dollars in revenue, but even more in losses.

Of course, Deepseek coming in, and building their LLM at a fraction of the cost ( reportedly it cost them $6M), raises other questions around how the West has optimized building LLMs, the astronomical fund raises, and valuations of AI companies currently.
This also brings up an interesting question around building your own LLMs vs using existing models. Deepseek seems to have proven that at a (relatively) cheaper cost, one can build their own LLM, so costs suddenly are not a barrier. But what they have also done is made usage of LLMs much cheaper (Ex: GPT o1 costs $60 / 1M of output tokens, Deepseek (r1) costs $2.19 / 1M of input tokens). Note: The calculation of how much text = how many tokens seems to be a bit arbitrary, but you can check it out here to build a perspective: here
So instead of not building their own LLMs because its much more expensive, now it’s more of cost benefit decision. Should I build my own at this cheaper cost, or use the APIs of existing models (the prices of which will go down further as costs are optimized).
Assuming that costs are optimized to some extent, what the revenue bet here then?
There are multiple ways to monetize.
1) API access: This is pretty standard. Integrate LLMs such as ChatGPT/ GPT4 into a business service to help write code, draft emails, create chatbots by leveraging the ChatGPT model. This is monetized per API call. Customized solutions can also be built by leveraging this, either if someone wants to build a fine tuned LLM on specific data. There could be some data privacy issues with regards to fine tuning, so the jury’s still out on how that will play out.
2) The bigger use case here in my opinion are AI agents which leverage LLMs. Most LLMs (such as OpenAI APIs) charge basis input and output tokens (whatever text the user inputs, and the output text of the LLM), so the more prompts, and the larger the output, the more opportunity to monetize there is. The AI agent market is projected to be ~$140B in 2033, maybe more. So if this market takes off, then the API monetization in training / using LLMs to power AI agents is something that could be quite lucrative.
3) Subscription services: A freemium sort of model, where paying subscribers can get access to better services - this can be B2B or B2C. ex. ChatGPT pro, Claude Pro, Perplexity Pro. This can be B2B or B2C. Pretty standard stuff.
4) The big bet, for LLM chats at least (Perplexity, ChatGPT, Gemini, etc.) is Ad revenue: which is where the significant chunk of money seems to lie.
Example: Alphabet (Google’s parent company) in 2023, generated close to ~$238B of revenue from ads, which was ~77% of its entire revenue. Out of this, Google Search contributed to $175B, or ~73% of Alphabet’s ad revenue. The search engine ads market is expected to hit ~$500B by 2029. And that’s the big money spinner: it’s not so much about the API access.
That’s Perplexity’s bet. Perplexity isn’t actually a LLM. All others: ChatGPT, Meta AI, Gemini etc have developed their own LLMs. Perplexity has integrated with multiple LLMs to optimize its search engine. It retrieves information directly from the web and other databases at the time of the query. Other models rely on pre-existing knowledge that the model has been trained on: there is usually a cutoff date.
Somewhere, as LLMs get more optimized, the margins will thin (such as what Deepseek has done), and volumes is what will drive revenues. And it’s tough for everyone to play on volumes. It is the client facing tools: LLM chats (ChatGPT), AI powered search engines (Perplexity), AI agents etc that offer a lot of monetization potential.
I could argue that a model here is a commodity. Maintaining a LLM is hard, and not everyone really needs to do it. What really matters is how you motivate users to come to your platform so you can tap into that ad revenue.
I expect revenues and costs to move in tandem: the more people use it, the higher the cost of inference, and more energy this sucks up. So to be able to sustain this, we need to be able to optimize costs:
While building/ training an LLM is a one-time cost (CAPEX) which is significant, high, the cost of running/ inference of LLMs (OPEX) is also high when you think about scale. Companies have been trying to solve this by two possible ways today:
Custom chips: Rather using a standard H100, companies like Groq, are building custom chips for a family of LLMs. The architecture of this chip is optimized for LLM specific models. Further, they also remove unnecessary components which reduce further complexity and also make it energy efficient thus reducing the running cost. Because they have reduced unnecessary components, they can also maximize transistors for computation rather than for managing data flow.
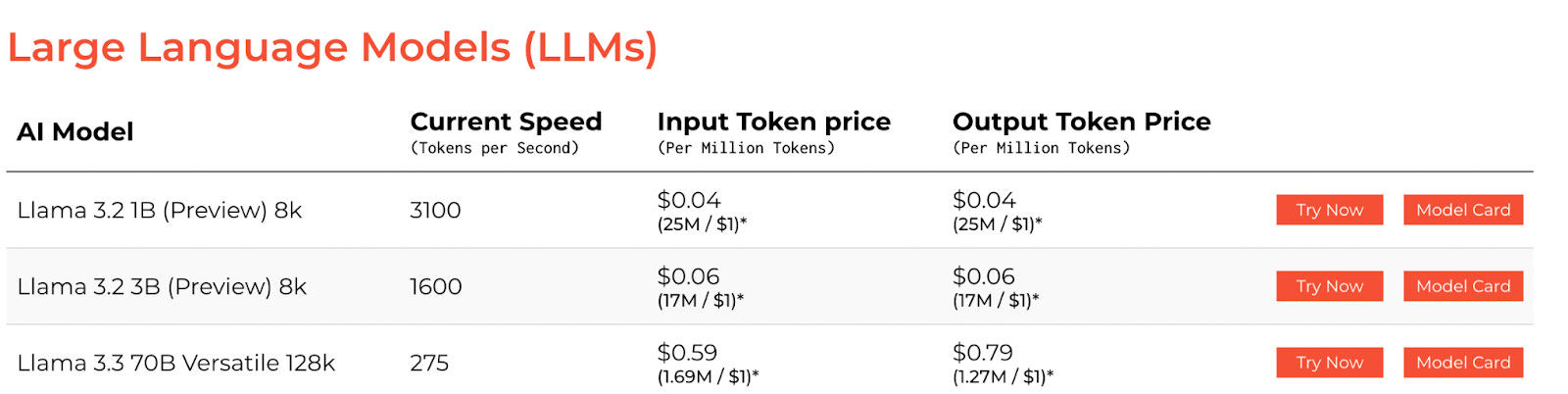
Take a look at the image below. If I want to run & deploy Llama, it’s way cheaper if I use Groq chips vs the standard Nvidia H100 chips, because Groq is optimized for LLM specific models. (ChatGPT if you recall, costs $2.5 / 1M input tokens, and they’re optimized for Nvidia H100 chips. Groq costs $0.04 / 1M input tokens)
Prompt-caching can save computation energy: This is an advanced technique which uses architecture of LLMs to reduce the cost. When you have a large prompt where you can reuse parts of the prompt, you can re-use the already processed computation or “cache” the prompt. This saves computation and also reduces response time.
Architecture optimization allows for more cost efficient inference: You can check out this article here. This is specifically for those use cases, where training and deployment of multiple different in-house LLM models are needed, especially when there are multiple LLMs being trained and deployed, companies such as Pipeshift & Simplismart are building modular infrastructure, which allows optimization for workload and GPU usage - think of it as AI workload and infra orchestration. This is more from a cost optimization perspective
The second question on sustainability is the sheer amount of energy these models require to run:
Training LLM models requires a lot of GPUs. GPUs require a lot of energy. Models like GPT, require enormous amounts of energy. Reportedly, ChatGPT used 1,287 megawatt-hours (MWh) of electricity—equivalent to the energy usage of an average American household over 120 years (source)
And that’s just the energy required for training. There is also energy required to process daily requests. Example: Each query to ChatGPT consumes approximately 2.9 watt-hours (Wh) of electricity. This is nearly ten times more than what is required for a standard Google search. With around 200 million queries processed daily, the total energy consumption adds up significantly. Altogether, data centers use more electricity than most countries, barring the USA and China.
Big Tech can’t hope to rely on conventional sources of power to meet their existing energy demands - because of the existing built capacity, tech’s public commitments to sourcing clean energy, and the curbs on building new coal-fired plants (in countries hoping to meet their energy transition targets)
The risk of an unstable grid: if we use existing power sources to power the increased demand, we risk creating an imbalance within the power grid
The pressure that large data centers are applying on the grid is destabilizing the quality of the power supply to homes. Research shows that the worst distortions of power quality occur in homes located within 20 miles of significant data-centre related activity. This concern is not just aesthetic - surges or lags in power demand can significantly damage home appliances and set off home fires, and we’ve seen the scale of destruction that fires can unleash when egged on by winds. An unstable grid is bad, bad news - for every stakeholder involved. Tech needs new sources of power. Now.
To be able to power the increasing energy needs of AI data centres: Nuclear seems to be the answer
Nuclear has always been the proverbial light at the end of the tunnel - to solve all of humanity’s energy needs. The hanging sword of nuclear plant failures, however, always make the journey to the light at the end of that tunnel stretch out farther into the distance. It appears now, however, that nuclear might be living out its nine lives, with the sheer demand for AI. Amazon bought a data center adjacent to a nuclear power plant in Pennsylvania - but its behind-the-meter purchase of electricity ran into trouble with regulators, and the purchase failed. Microsoft has also entered into an agreement with Constellation Energy to restart a shuttered nuclear reactor on Three Mile Island—the site of the worst nuclear disaster in U.S. history. Late in 2024, just two days apart, Google and Amazon both announced investments in startups developing Small Modular Reactors.

The Small Module Reactor (SMR): This is whae everyone seems to be betting on, big tech has already announced investments here
Small Modular Reactors are smaller, more modular, and more technologically advanced than our conventional nuclear reactors - SMRs usually have a generation capacity of a third of the conventional nuclear reactors. Prefabricated units of SMRs can be designed, manufactured and shifted to the plant site. SMRs can be constructed on sites not suitable for larger nuclear reactors, and are bolstered with more safety features in comparison. They can also be installed directly into the existing power grid, and don’t always need additional infrastructure.
SMRs are ~5 years from being commercially viable in the US. China is building an SMR expected to be operational in 2026. Russia has a “floating” SMR, operational from 2020. Globally, over 80 commercial SMRs are being constructed, and this does seem to be the way forward to meet the massive AI-led uptick in energy demand.
However, with nuclear energy comes also the potential of catastrophic accidents, and a lot of countries, especially European countries have very strong stances against nuclear energy, and especially foreign investment in the same, so this will have to have regulatory blessing. Going nuclear isn’t a bad option - it will definitely shorten the timelines on energy transition for countries. Just as long as regulators act as the guardrails of safety and due process.
Assuming energy problems are figured out, from a cost perspective, Deepseek has turned the LLM industry on its head: suddenly building LLMs are accessible to everyone: is there a risk of commoditizing?
Well, originally my view was, looking at the costs involved: OpenAI for example will spend $8B in ‘24 in training and maintaining its models, that this will only be a finite number. The entities that can actually build and maintain are mostly big tech: your FAANG companies.
With Deepseek coming in, with its model reportedly costing $6-$10M to train has changed all this. Suddenly this makes LLMs accessible to non-big tech companies. So then the cost & sustainability angle goes away (especially if nuclear energy comes in). And even the model & architecture of LLMs is similar, all that differs is the number of parameters, and the number of attention & feedforward layers that the training algorithm has built in.
Deepseek has turned pricing on its head as well. OpenAI APIs are pretty expensive, at ~$60/ 1M output tokens. Deepseek is ~95% cheaper ($2.19 / 1M output tokens), it’s trained on 671B parameters vs OpenAI of 1.8T, AND it performed on par / out performed on key benchmarks vs OpenAI. So it’s not that it’s an inferior model.),
My own perspective of LLMs, especially looking at optimizations, is that it’ll become somewhat of a commodity, if everyone can build them. And of course, the model of building and maintaining a LLM requires effort: maintaining data centres, energy sources, labelling the data etc, which may not be worth a new company's while, especially if the costs become so optimized.
I would actually compare LLMs to DPI (Digital Public Infrastructure) in India. At its core, these are rails that can be used to build products upon.
LLMs will act as a foundation on which the next era of companies will be built
Perplexity is a great example of using LLMs as a platform, and building on top of them: it uses GPT4, Mistral AI, and Claude to understand the nuance of a user query, uses its search engine to index the web in real time, and then summarizes the response.
But whether folks will use and fine tune existing models, or build their own, only time will tell: after seeing what Deepseek has done, cost & investment is not a blocker. But it opens up opportunities such as “LLM as a service,” or subsets of what help to build, train and deploy LLMs.
Verticalized AI agents are the BIG thing that LLMs will power, which are basically the future of services & SaaS companies.
And if AI agents are the future, then you need company software & tools that are compatible with AI agents & LLM integrations, so apart from AI agents, I see an opportunity for companies to build new CRMs, Financial, Accounting Tools which are AI & AI agent compatible, OR provide a way for existing systems to upgrade to be AI compatible. Even opportunities such as “AI agents as a service” which enable companies to build and deploy their own AI agents is something that is coming up. And that’s probably why there is so much investment in AI agent companies. The AI agent start-ups of today will most probably replace a large bunch of the services business of tomorrow. And LLMs will power all of that.
A key point to note is that AI agents are essentially meant to replace a human worker, so they require very complex workflows and training: the number of steps compound the error rate, so this seems to be a verticalized play.
The opportunity in GenAI is immense. To deliver on the promise of this opportunity, tech will continue to push for more nuclear power, & more efficient infrastructure. Which will be driven through investments, working with regulators and influencing public opinion.
 |
|
 | A guest post by
|